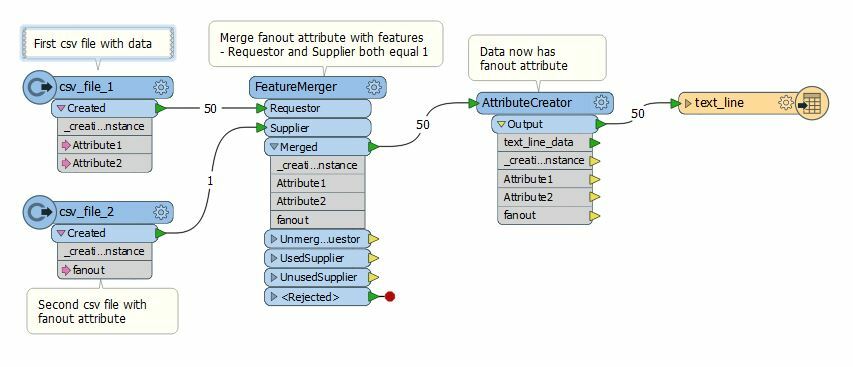
I have a workspace that reads multiple features from a CSV file, transforms them and then writes the results to a custom text format (using text_line_data).
I would like to set the name of the output file at run-time based on a 4 digit integer value read from a second input CSV file. For example, if the integer is 2934 then the relevant attribute is set to OUTPUT_FILENAME=output_2934.txt
However, I am getting in a mess trying to configure the output text writer. If I fanout on OUTPUT_FILENAME, I get two output files (rather than the desired single file) when I run the workspace. The files produced are output_2934.txt (with no content) and output_.txt (with correct content). If I don't set the fanout, I can't see how to configure OUTPUT_FILENAME.
Is my approach fundamentally flawed? Any help much appreciated.