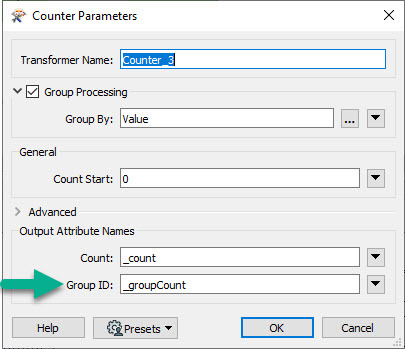
@patmhid We don't have anything out of the bx. If you can order your features by the grouping attribute, then you can use the Adjacent Feature option in AttributeCreator to create group counts. I've attached an example workspace.
Similarly, that's the Solution I use in my Workspaces: Sorter + AttributeCreator
AttributeCreator
Enable Adjacent Feature Attributes: On
Prior Features: 1
Conditional Value: If @Value(GroupAttribute)=@Value(feature[-1].GroupAttribute) Then @Value(feature[-1].GroupID) Else @Value(feature[-1].GroupID)+1
The only thing I found was that at least in 2018.1, the FME Workspace Editor wants you to create the GroupID Attribute with a separate, preceding AttributeCreator first that initialises it to a default Dummy Value, otherwise an AttributeCreator that simultaneously tries to use Adjacent Feature Handling and create a new Attribute that doesn't yet exist in the Schema and is calculated using an Adjacent Feature Value will report itself as an "Invalid Transformer" in the workspace, even though it WILL run fine when executing the workflow!











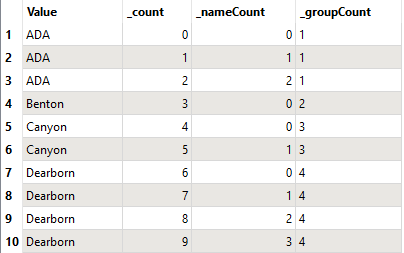
 results:
results: