")

Hi All,
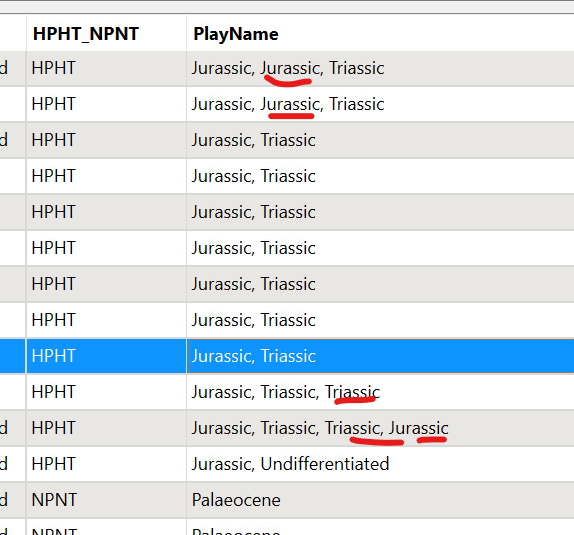
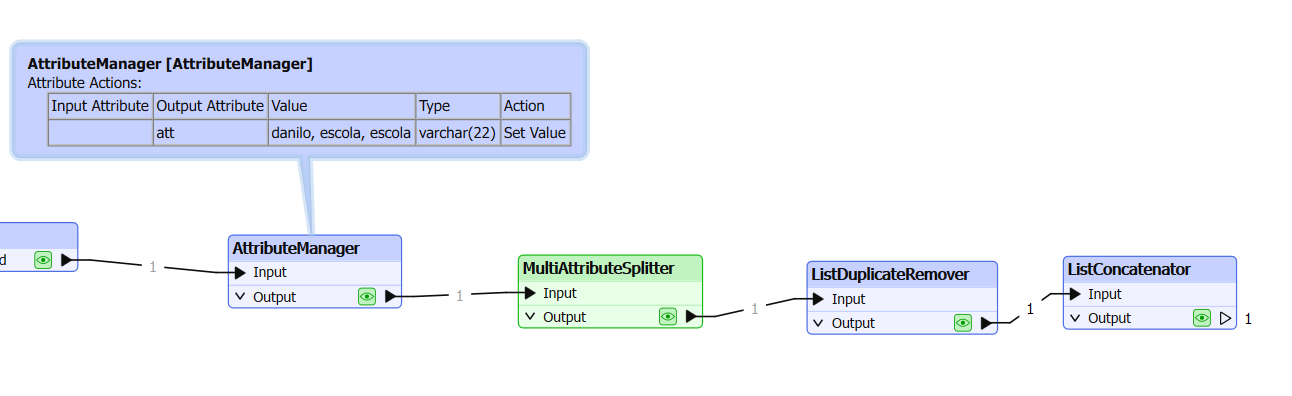
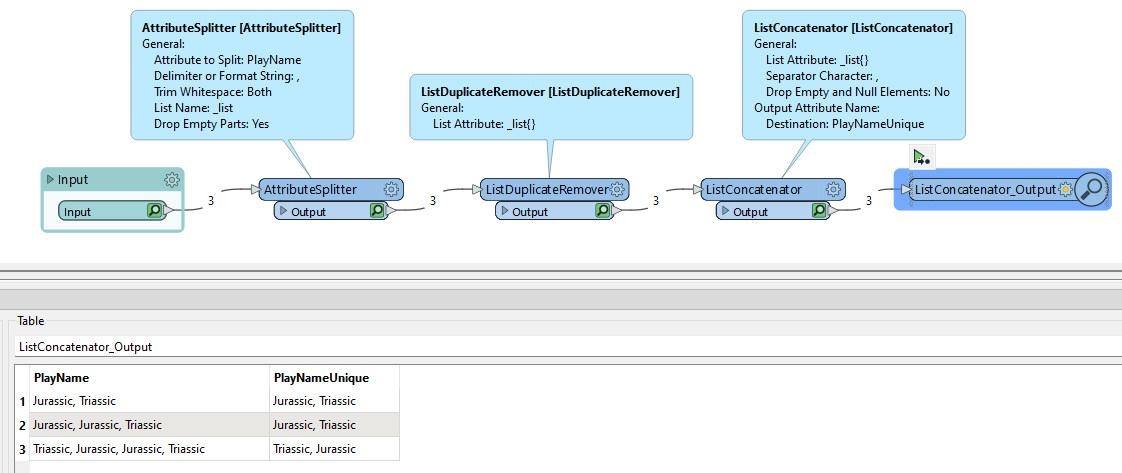
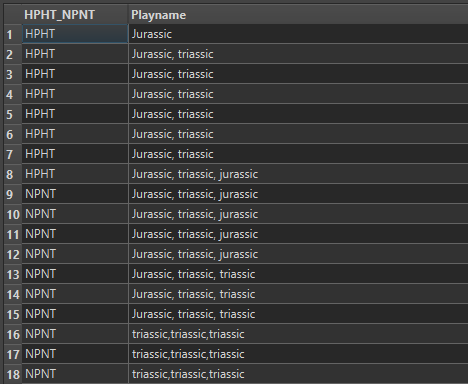
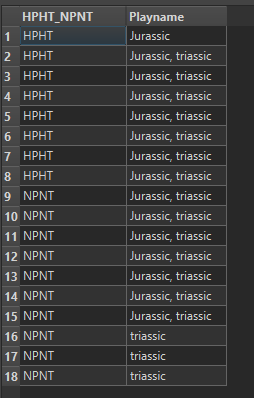
Anyone could help me with this specific question in FME? I want to remove the repeated words in each row, e.g. A,B,C,A,B in a row, the A, B have been repeated twice, I would like to remove the repeated A and B only. please see attached the sample data. many thanks.