

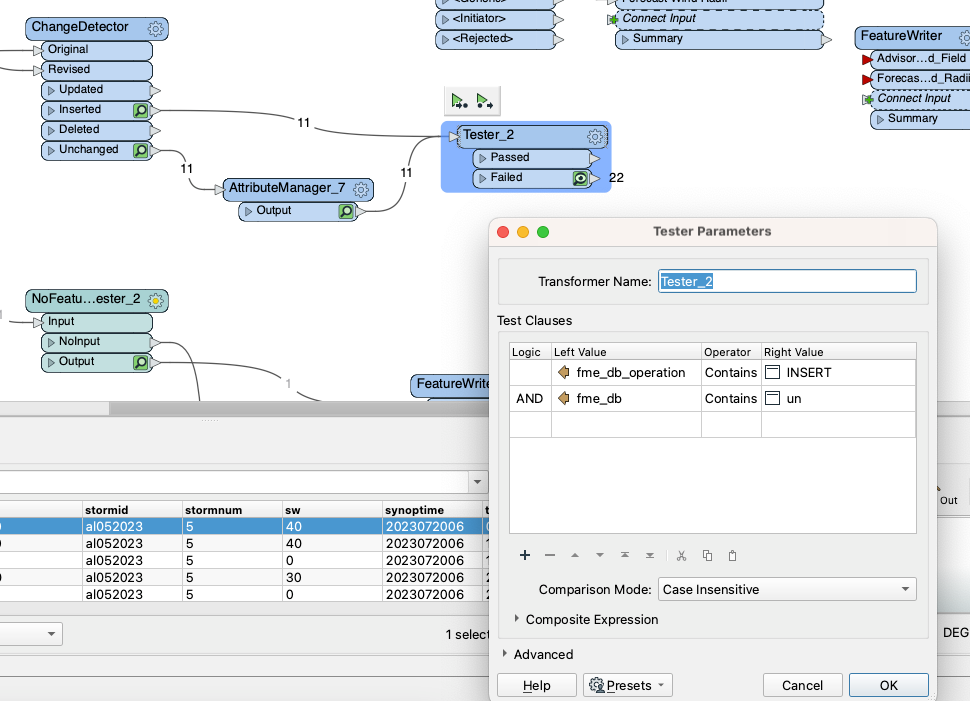
I am trying to get the result when both "insert" and "unchanged" have values, but if one of them doesn't have a value, it's going to fail. Can anyone please help?

Question
Tester filter not working




Login to the community
No account yet? Create an account
An FME Account is required to contribute
LoginEnter your E-mail address. We'll send you an e-mail with instructions to reset your password.