

I intend to use the FME software to create a database in postgis having as reader and writer the postgis. My reader is a line table and my writer will be two multipolygon tables. One of the tables has large polygons (for example the United States of America) and another has smaller polygons (for example the various States of the United States of America). The database I want to create in the end, will be relational type. I can get the final result I want, but to achieve it I have to create and run two separate FME Workbenches, but I plan to be able to achieve the same end result in just one FME Workbench. The reason i need two separate FME Workbenchs is because i do not have primary keys and foreign keys. For this reason, I use the first Workbench to generate primary keys and the second Workbench to copy and populate the foreign keys in the tables so that they can be related through the primary and foreign keys. Can anyone tell me how can I generate primary keys before loading the Feature Writer and relating them in one single Workbench?
Best regards,CFID Generator Transformer
- May 18, 2018
- 19 replies
- 290 views
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
19 replies

- May 18, 2018

Hi @sergio_ferreira, there should be some ways. A possible way is: write all features into the two tables with two FeatureWriters, then add required constraints (primary key, foreign key) to the tables with SQL statements, which can be executed by a SQLExecutor. e.g.
SQL statemtns
FME_SQL_DELIMITER ;
alter table table1 add constraint pk_table1 primary key (id);
alter table table2 add constraint pk_table2 primary key (id);
alter table table2 add constraint fk_table2_table1 foreign key (id) references table1 (id);
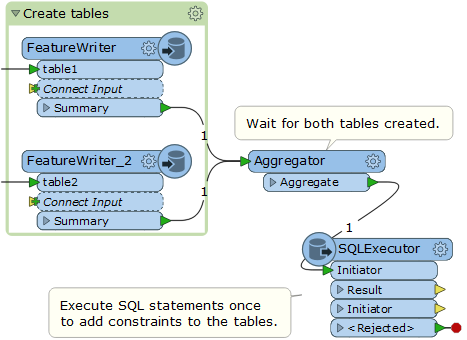
- Author
- May 21, 2018
Hello Takashi,
Thanks for your answer.I wonder if there's another way to solve my problem. I tried to follow your guidelines and suggestions but without success. Maybe because of my lack of knowledge / experience or because I did not provide all the necessary and important information. In my previous message I did not mention some aspects that can be important and make difference. The Databases, which contain the Target Tables, where I will write the data processed in the FME, already have the whole structure created, including the restrictions/constraints of primary keys and foreign keys. The Tables in these Databases have already been created in PostgreSQL / PostGIS, with SQL language, where I have already defined all the restrictions of primary keys and foreign keys (I only need to load the data to the already created and well defined Databases). In my first Workbench I have the Feature Writer ready to receive all the data I want except the foreign key. What happens is that in PostgreSQL / PostGIS I immediately set the primary keys to be sequential, so that the data being loaded into the Workbench Feature Writer will automatically generate those primary keys in the Database because they were defined in the PostGIS. The reason why I did this is because the starting data are not the same as the arrival data, that is, they undergo a set of transformations in the FME until the desired final table is reached. So, in my final table, I set the field of my primary key to be of the sequence type, in order to generate the primary keys, since I still do not have them. Since I do not have them and one of the tables will receive as the foreign key the primary key of the other table that also has the primary key field of the sequence type, I was forced to create another Workbench to make a Feature Merge between the table that will have all the fields I want and receive as the foreign key the primary key of the other table that will provide. I just intended, if possible, to use a tool that generated the primary keys before loading in the final tables (Feature Writer) and the value of the primary key of one table was the same value of the foreign key of the other table, so as to mater the relationship between the two tables of different hierarchy (for example Table country (USA) - States Table (USA States). In this way I would avoid having to run two Workbenches and would only run one Workbench. Can I send my two Workbench templates to any of you to realize what I really need and where I am?My Workbench is very large, so it becomes virtually impossible to put print screen here.If it is possible to send my models, how should I proceed?Best regards,Sérgio Ferreira
- Author
- May 21, 2018
Sorry, when I mention Feature Writer, I want to mention the FME Workbench Writer.
- May 21, 2018
Hello Takashi,
Thanks for your answer.I wonder if there's another way to solve my problem. I tried to follow your guidelines and suggestions but without success. Maybe because of my lack of knowledge / experience or because I did not provide all the necessary and important information. In my previous message I did not mention some aspects that can be important and make difference. The Databases, which contain the Target Tables, where I will write the data processed in the FME, already have the whole structure created, including the restrictions/constraints of primary keys and foreign keys. The Tables in these Databases have already been created in PostgreSQL / PostGIS, with SQL language, where I have already defined all the restrictions of primary keys and foreign keys (I only need to load the data to the already created and well defined Databases). In my first Workbench I have the Feature Writer ready to receive all the data I want except the foreign key. What happens is that in PostgreSQL / PostGIS I immediately set the primary keys to be sequential, so that the data being loaded into the Workbench Feature Writer will automatically generate those primary keys in the Database because they were defined in the PostGIS. The reason why I did this is because the starting data are not the same as the arrival data, that is, they undergo a set of transformations in the FME until the desired final table is reached. So, in my final table, I set the field of my primary key to be of the sequence type, in order to generate the primary keys, since I still do not have them. Since I do not have them and one of the tables will receive as the foreign key the primary key of the other table that also has the primary key field of the sequence type, I was forced to create another Workbench to make a Feature Merge between the table that will have all the fields I want and receive as the foreign key the primary key of the other table that will provide. I just intended, if possible, to use a tool that generated the primary keys before loading in the final tables (Feature Writer) and the value of the primary key of one table was the same value of the foreign key of the other table, so as to mater the relationship between the two tables of different hierarchy (for example Table country (USA) - States Table (USA States). In this way I would avoid having to run two Workbenches and would only run one Workbench. Can I send my two Workbench templates to any of you to realize what I really need and where I am?My Workbench is very large, so it becomes virtually impossible to put print screen here.If it is possible to send my models, how should I proceed?Best regards,Sérgio Ferreira
- Author
- May 22, 2018
Hello Takashi,
I am generating the primary key values automatically with a "serial" type column, because I do not have primary keys for the tables.
So, in the first Workbench I generate the primary keys automatically with a "serial" type column, for each of the tables.
Subsequently, in the second Workbench I make a copy of the primary keys from each of the tables of the Database for the same tables of another Database (practically a copy of the first database).
Also, in the second Workbench, for the second Database, I make a Feature Merger between the two different hierarchy tables, which are related, in order to get from the supplier (top hierarchical table) its primary key that corresponds to foreign key of the requestor (lower hierarchical table). Only at this moment I can get the relational database that i pretend.
Is there any way in the same Workbench to load the primary keys into the tables and then use them to load foreign keys on the lower hierarchical tables? Or, generate primary keys before loading the tables and after generating those keys, use them to load the top hierarchy tables as primary keys and still use them to load the lower hierarchy tables as foreign keys?
What I intend is stop having to run two Workbench, and to have only one Database, in this case relational, not needing to have the first Database that is not relational and I only use it as a mean to generate primary keys.
Best regards,
Sérgio Ferreira
- May 22, 2018
Hello Takashi,
I am generating the primary key values automatically with a "serial" type column, because I do not have primary keys for the tables.
So, in the first Workbench I generate the primary keys automatically with a "serial" type column, for each of the tables.
Subsequently, in the second Workbench I make a copy of the primary keys from each of the tables of the Database for the same tables of another Database (practically a copy of the first database).
Also, in the second Workbench, for the second Database, I make a Feature Merger between the two different hierarchy tables, which are related, in order to get from the supplier (top hierarchical table) its primary key that corresponds to foreign key of the requestor (lower hierarchical table). Only at this moment I can get the relational database that i pretend.
Is there any way in the same Workbench to load the primary keys into the tables and then use them to load foreign keys on the lower hierarchical tables? Or, generate primary keys before loading the tables and after generating those keys, use them to load the top hierarchy tables as primary keys and still use them to load the lower hierarchy tables as foreign keys?
What I intend is stop having to run two Workbench, and to have only one Database, in this case relational, not needing to have the first Database that is not relational and I only use it as a mean to generate primary keys.
Best regards,
Sérgio Ferreira
- May 22, 2018
- Author
- May 24, 2018
Hello Takashi,
Thank you again for all your help.
The solutions you gave me seem to work.
However, I still have problems.
In the connection between the FeatureWriter and the FeatureReader I have a value (for example 1) and in the connection between the FeatureReader and the FeatureMerger I have a value equal to the number of records that exists in the table that is used to be read.
Should not the value of the connection between FeatureWriter and FeatureReader be the same as the connection value between FeatureReader and FeatureMerger? Or does FeatureReader always read the entire read table?
However, my problem is with FeatureMerger, because i think it only accepts the number of records equal to the connection value between FeatureWriter and FeatureReader, rejecting the remaining (repeated) records.
When I load data to the table at the first time (still no data in the table), no data is rejected and the process is completed successfully. When I repeat the entire procedure and load data into the table (now with stored values from the previously processes) I get the FeatureMerger rejection error.
What should I do to overcome this problem?
Is there any possibility or a way to indicate in the output of the FeatureReader that I just only want input values from the FeatureReader?
Or in the connection between FeatureReader and FeatureMerger that I just want the input value of the FeatureReader?
Or indicate in FeatureMerger that I only want the input value of the FeatureReader?
Or tell to FeatureMerger to ignore the values that are rejected by itself?
Best regards, Sérgio Ferreira
- May 24, 2018
Hello Takashi,
Thank you again for all your help.
The solutions you gave me seem to work.
However, I still have problems.
In the connection between the FeatureWriter and the FeatureReader I have a value (for example 1) and in the connection between the FeatureReader and the FeatureMerger I have a value equal to the number of records that exists in the table that is used to be read.
Should not the value of the connection between FeatureWriter and FeatureReader be the same as the connection value between FeatureReader and FeatureMerger? Or does FeatureReader always read the entire read table?
However, my problem is with FeatureMerger, because i think it only accepts the number of records equal to the connection value between FeatureWriter and FeatureReader, rejecting the remaining (repeated) records.
When I load data to the table at the first time (still no data in the table), no data is rejected and the process is completed successfully. When I repeat the entire procedure and load data into the table (now with stored values from the previously processes) I get the FeatureMerger rejection error.
What should I do to overcome this problem?
Is there any possibility or a way to indicate in the output of the FeatureReader that I just only want input values from the FeatureReader?
Or in the connection between FeatureReader and FeatureMerger that I just want the input value of the FeatureReader?
Or indicate in FeatureMerger that I only want the input value of the FeatureReader?
Or tell to FeatureMerger to ignore the values that are rejected by itself?
Best regards, Sérgio Ferreira
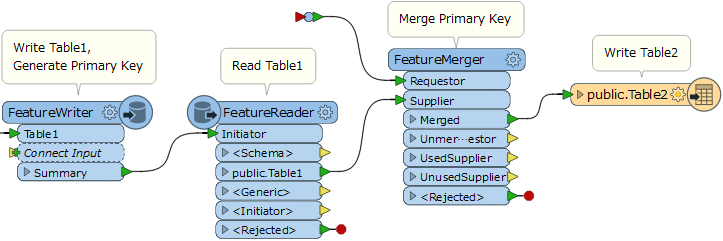
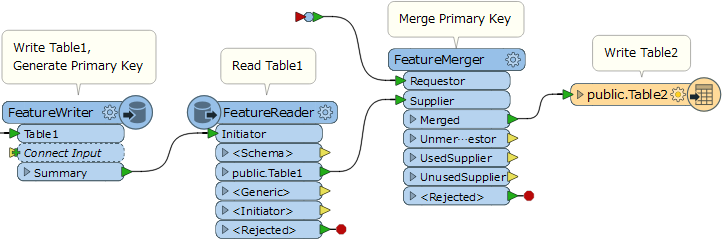
Were you able to write the first table with the FeatureWriter and then read back the records having primary key with the FeatureReader?
- Author
- May 24, 2018
Yes Takashi,
I've record the data to the first table (Top Hierarchical Table) with the FeatureWriter and then read those records (already with the primary key) with the FeatureReader. Then I make FeatureMerger of the data coming from the FeatureReader with the data that is to write to the second table (Lower Hierarchical Table).I also noticed that the foreign key stored in the second table is always the same, ie the primary key of the first record of the first table, not registering the value of the primary key of the remaining records of the first table. The second table only registers the values when I put a Connect Inspector on the rejected values of the second table, otherwise it gives error and does not register.
fme-featuremerger-error.jpg
- May 24, 2018
Yes Takashi,
I've record the data to the first table (Top Hierarchical Table) with the FeatureWriter and then read those records (already with the primary key) with the FeatureReader. Then I make FeatureMerger of the data coming from the FeatureReader with the data that is to write to the second table (Lower Hierarchical Table).I also noticed that the foreign key stored in the second table is always the same, ie the primary key of the first record of the first table, not registering the value of the primary key of the remaining records of the first table. The second table only registers the values when I put a Connect Inspector on the rejected values of the second table, otherwise it gives error and does not register.
fme-featuremerger-error.jpg
- Author
- May 24, 2018
Takashi,
When I connect an Inspector to the FeatureReader output port, I do not only get the record that corresponds to the Workspace that I'm running at the moment, but all the records corresponding to all the Workspaces that have been run so far and recorded in the first table. But the record that interests to me is the record that corresponds to the Workspace, I'm running at the moment.
fme-featuremerger-error.jpg
- May 24, 2018
Takashi,
When I connect an Inspector to the FeatureReader output port, I do not only get the record that corresponds to the Workspace that I'm running at the moment, but all the records corresponding to all the Workspaces that have been run so far and recorded in the first table. But the record that interests to me is the record that corresponds to the Workspace, I'm running at the moment.
fme-featuremerger-error.jpg
- Author
- May 25, 2018
Hello Takashi,
The FeatureReader generated the desired records.
However, as you can see in the attached image, the first table (FME FeatureReader Inspector) shows the result of the FeatureReader Inspector after running the Workspace at the second time. The result are all of the records in Table 1. The first result contains the ID of Table 1 (id_nut1 = 1) that I want to cross with Table 2 at the first time I run the Workspace. The second result contains the ID of Table 1 (id_nut1 = 2) that I want to cross with table 2 at the second time I run the Workspace. What I want is for each time I run the Workspace the new record generated in the FeatureWriter of Table 1 is used in the FeatureMerger with Table 2 so that in the first Workspace Table 2 will have (id_nut2 = 1 and id_nut1 = 1; id_nut2 = 2 and id_nut1 = 1; id_nut2 = 3 and id_nut1 = 1; id_nut2 = 4 and id_nut1 = 1; id_nut2 = 5 and id_nut1 = 1) and in the second Workspace, Table 2 will have (id_nut2 = 6 and id_nut1 = 2; id_nut2 = 7 and id_nut1 = 2; id_nut2 = 8 and id_nut1 = 2; id_nut2 = 9 and id_nut1 = 2; id_nut2 = 10 and id_nut1 = 2) and so on.
As you can see in the first table (FME FeatureReader Inspector) and the second table (PostGIS Table 1) presented in the image, the records in PostGIS Table 1 are well done, but whenever I invoke the FeatureReader it does not only read the new records, but all records. I do not know if anything can be done here so that only the new records generated and stored in Table 1 of each Workspace run are extracted in the FeatureReader.
In the third table (FME FeatureMerger Inspector - accepted data) and fourth table (FeatureMerger Inspector - rejected data), we can verify that the accepted data in FeatureMerger always corresponds to the first record generated and introduced in PostGIS Table 1, after running the first Workspace and the rejected data are the remaining records generated and entered in Table 1 of PostGIS after running the second Workspace and so on. The problem seems to be here, because I intend the exact opposite. I want the accepted data to be the data that is being rejected and the rejected data to be the data that is being accepted. As you can see in the fifth table (PostGIS Table 2), PostGIS is registering data for each Workspace run, but the id_nut1 is always equal to 1, which is wrong. The id_nut1 of Table 2 must always be equal to the id_nut1 of Table 1 that is being run, ie in this case it should be, for the values between id_nut1 = 6, 7, 8, 9 and 10 should be id_nut1 = 2.
Best regards,
Sérgio Ferreira
fme-and-postgis-results.jpg
- May 25, 2018
Hello Takashi,
The FeatureReader generated the desired records.
However, as you can see in the attached image, the first table (FME FeatureReader Inspector) shows the result of the FeatureReader Inspector after running the Workspace at the second time. The result are all of the records in Table 1. The first result contains the ID of Table 1 (id_nut1 = 1) that I want to cross with Table 2 at the first time I run the Workspace. The second result contains the ID of Table 1 (id_nut1 = 2) that I want to cross with table 2 at the second time I run the Workspace. What I want is for each time I run the Workspace the new record generated in the FeatureWriter of Table 1 is used in the FeatureMerger with Table 2 so that in the first Workspace Table 2 will have (id_nut2 = 1 and id_nut1 = 1; id_nut2 = 2 and id_nut1 = 1; id_nut2 = 3 and id_nut1 = 1; id_nut2 = 4 and id_nut1 = 1; id_nut2 = 5 and id_nut1 = 1) and in the second Workspace, Table 2 will have (id_nut2 = 6 and id_nut1 = 2; id_nut2 = 7 and id_nut1 = 2; id_nut2 = 8 and id_nut1 = 2; id_nut2 = 9 and id_nut1 = 2; id_nut2 = 10 and id_nut1 = 2) and so on.
As you can see in the first table (FME FeatureReader Inspector) and the second table (PostGIS Table 1) presented in the image, the records in PostGIS Table 1 are well done, but whenever I invoke the FeatureReader it does not only read the new records, but all records. I do not know if anything can be done here so that only the new records generated and stored in Table 1 of each Workspace run are extracted in the FeatureReader.
In the third table (FME FeatureMerger Inspector - accepted data) and fourth table (FeatureMerger Inspector - rejected data), we can verify that the accepted data in FeatureMerger always corresponds to the first record generated and introduced in PostGIS Table 1, after running the first Workspace and the rejected data are the remaining records generated and entered in Table 1 of PostGIS after running the second Workspace and so on. The problem seems to be here, because I intend the exact opposite. I want the accepted data to be the data that is being rejected and the rejected data to be the data that is being accepted. As you can see in the fifth table (PostGIS Table 2), PostGIS is registering data for each Workspace run, but the id_nut1 is always equal to 1, which is wrong. The id_nut1 of Table 2 must always be equal to the id_nut1 of Table 1 that is being run, ie in this case it should be, for the values between id_nut1 = 6, 7, 8, 9 and 10 should be id_nut1 = 2.
Best regards,
Sérgio Ferreira
fme-and-postgis-results.jpg
- Author
- May 25, 2018
Hello Takashi,
The FeatureReader generated the desired records.
However, as you can see in the attached image, the first table (FME FeatureReader Inspector) shows the result of the FeatureReader Inspector after running the Workspace at the second time. The result are all of the records in Table 1. The first result contains the ID of Table 1 (id_nut1 = 1) that I want to cross with Table 2 at the first time I run the Workspace. The second result contains the ID of Table 1 (id_nut1 = 2) that I want to cross with table 2 at the second time I run the Workspace. What I want is for each time I run the Workspace the new record generated in the FeatureWriter of Table 1 is used in the FeatureMerger with Table 2 so that in the first Workspace Table 2 will have (id_nut2 = 1 and id_nut1 = 1; id_nut2 = 2 and id_nut1 = 1; id_nut2 = 3 and id_nut1 = 1; id_nut2 = 4 and id_nut1 = 1; id_nut2 = 5 and id_nut1 = 1) and in the second Workspace, Table 2 will have (id_nut2 = 6 and id_nut1 = 2; id_nut2 = 7 and id_nut1 = 2; id_nut2 = 8 and id_nut1 = 2; id_nut2 = 9 and id_nut1 = 2; id_nut2 = 10 and id_nut1 = 2) and so on.
As you can see in the first table (FME FeatureReader Inspector) and the second table (PostGIS Table 1) presented in the image, the records in PostGIS Table 1 are well done, but whenever I invoke the FeatureReader it does not only read the new records, but all records. I do not know if anything can be done here so that only the new records generated and stored in Table 1 of each Workspace run are extracted in the FeatureReader.
In the third table (FME FeatureMerger Inspector - accepted data) and fourth table (FeatureMerger Inspector - rejected data), we can verify that the accepted data in FeatureMerger always corresponds to the first record generated and introduced in PostGIS Table 1, after running the first Workspace and the rejected data are the remaining records generated and entered in Table 1 of PostGIS after running the second Workspace and so on. The problem seems to be here, because I intend the exact opposite. I want the accepted data to be the data that is being rejected and the rejected data to be the data that is being accepted. As you can see in the fifth table (PostGIS Table 2), PostGIS is registering data for each Workspace run, but the id_nut1 is always equal to 1, which is wrong. The id_nut1 of Table 2 must always be equal to the id_nut1 of Table 1 that is being run, ie in this case it should be, for the values between id_nut1 = 6, 7, 8, 9 and 10 should be id_nut1 = 2.
Best regards,
Sérgio Ferreira
fme-and-postgis-results.jpg
In the example we are analyzing, Table 1 has only one polygon and Table 2 has 5 polygons that are contained in the same polygon of Table 1.
In this case it will always be the same id of Table 1 for all the polygons in Table 2.
But I will have other tables, for example Table 3 will have 4 polygons that will be contained in one of the polygons of Table 2 and another polygon of Table 2 will cointan 10 polygons of Table 3.
It will be the largest primary key of the Top Level Table for each polygon from Low Level Table that is contained in the specific polygon, depending on the crossing of the corresponding areas.
Meanwhile, I've been watching and changing the FeatureMerger settings and changed the following fields: - Process Duplicate Suppliers: before = no | now = Yes; - Conflict Resolution: before = Use Requestor | now = Use Supplier.
For the relation between Table 1 and Table 2 seem to be working.
Is this the solution?
Will it work for the other tables that contain more polygons at both the top and bottom levels?
Best regards,
Arigat?!
Sérgio Ferreira
fme-featuremerger-config.jpg
- May 25, 2018
In the example we are analyzing, Table 1 has only one polygon and Table 2 has 5 polygons that are contained in the same polygon of Table 1.
In this case it will always be the same id of Table 1 for all the polygons in Table 2.
But I will have other tables, for example Table 3 will have 4 polygons that will be contained in one of the polygons of Table 2 and another polygon of Table 2 will cointan 10 polygons of Table 3.
It will be the largest primary key of the Top Level Table for each polygon from Low Level Table that is contained in the specific polygon, depending on the crossing of the corresponding areas.
Meanwhile, I've been watching and changing the FeatureMerger settings and changed the following fields: - Process Duplicate Suppliers: before = no | now = Yes; - Conflict Resolution: before = Use Requestor | now = Use Supplier.
For the relation between Table 1 and Table 2 seem to be working.
Is this the solution?
Will it work for the other tables that contain more polygons at both the top and bottom levels?
Best regards,
Arigat?!
Sérgio Ferreira
fme-featuremerger-config.jpg
Which one among the records having the same "nut1_cod" should be merged to the requestor features? Need max "id_nut1" for each "nut1_cod" group?
- May 25, 2018
In the example we are analyzing, Table 1 has only one polygon and Table 2 has 5 polygons that are contained in the same polygon of Table 1.
In this case it will always be the same id of Table 1 for all the polygons in Table 2.
But I will have other tables, for example Table 3 will have 4 polygons that will be contained in one of the polygons of Table 2 and another polygon of Table 2 will cointan 10 polygons of Table 3.
It will be the largest primary key of the Top Level Table for each polygon from Low Level Table that is contained in the specific polygon, depending on the crossing of the corresponding areas.
Meanwhile, I've been watching and changing the FeatureMerger settings and changed the following fields: - Process Duplicate Suppliers: before = no | now = Yes; - Conflict Resolution: before = Use Requestor | now = Use Supplier.
For the relation between Table 1 and Table 2 seem to be working.
Is this the solution?
Will it work for the other tables that contain more polygons at both the top and bottom levels?
Best regards,
Arigat?!
Sérgio Ferreira
fme-featuremerger-config.jpg
id_nut1 in (select max(id_nut1) from "Table1" group by nut1_cod)
- Author
- May 25, 2018
Which one among the records having the same "nut1_cod" should be merged to the requestor features? Need max "id_nut1" for each "nut1_cod" group?
Takashi you are the man!!!
If I understood correctly what you mean, in your message, that is really my goal. So far, the results that I'm getting not only in Table 1 and 2 but also in the other tables are correct and appear to be the ones I want, although I still need to do some tests.
In fact, nut1_cod is the attribute used to merge between Table 1 and Table 2, as well as, the nut2_cod is the attribute to merge between Table 2 and Table 3, and so on.
Takashi, I really have to thank you for all your help, availability and interest shown up until now.
I work for a Portuguese governmental institution, and I am creating and developing a database that will serve to produce official products, metadata and also to feed National and European Spatial Data Infrastructures, at Dataset and Services level, in accordance with National Standards, European Directive (INSPIRE) and ISO.
As soon as I have finished my work, the Database will be ready not only to store data, but also to perform relational searches and answer to all kinds of requests.
You do an excellent work.
Takashi thank you a lot again for everything!
Best regards,
Arigat?!
Sérgio Ferreira
Community Stats
- 32,754
- Posts
- 124,208
- Replies
- 41,269
- Members
Login to the community
No account yet? Create an account
An FME Account is required to contribute
LoginEnter your E-mail address. We'll send you an e-mail with instructions to reset your password.