Hi there,
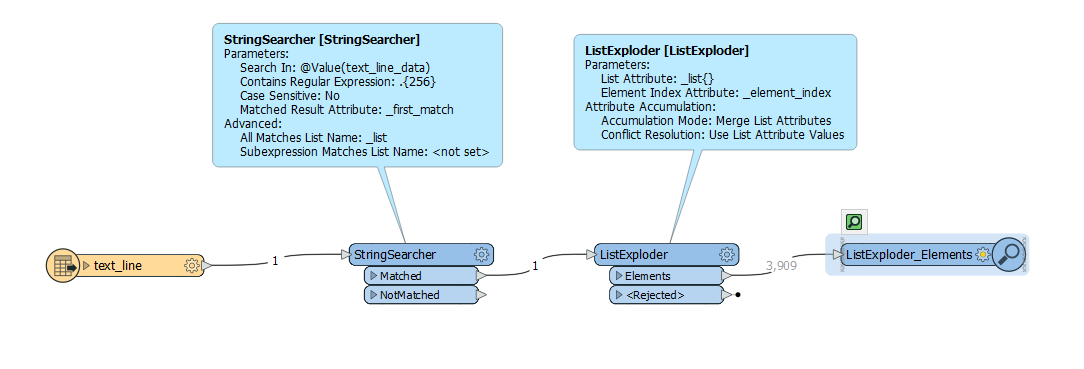
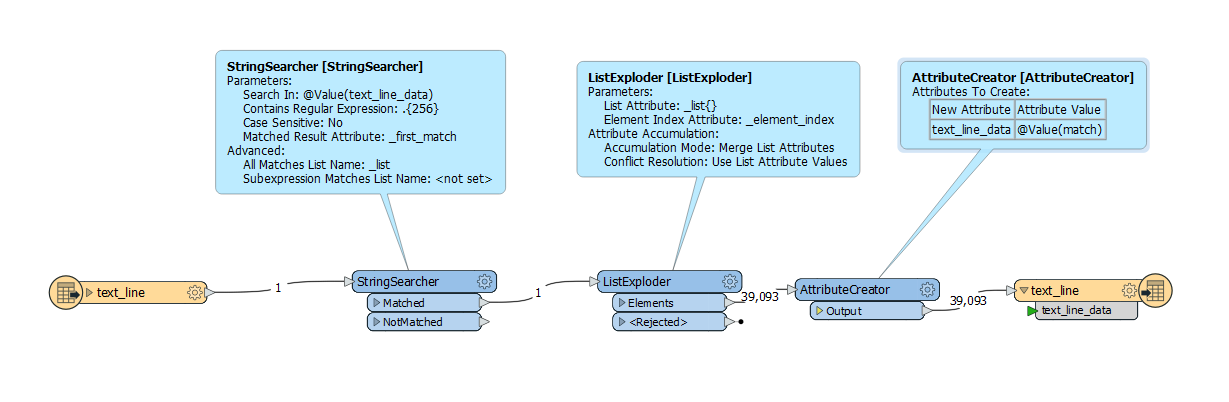
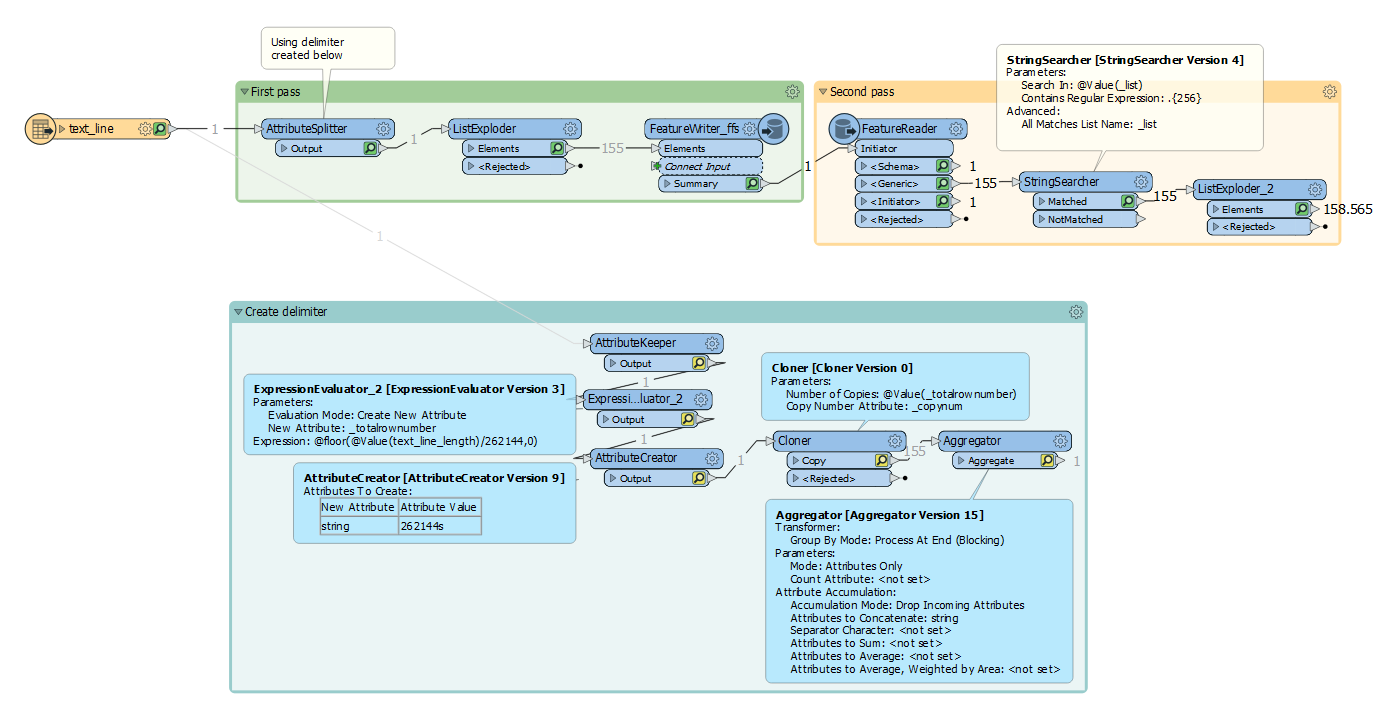
I have a text file containing 1 line with a length of ca. 40 billion characters. I need to parse the line into seperate lines, each 256 characters long.
I have tried multiple configurations looping with the AttributeSplitter (to parse the lines into a list and write it ) in conjunction with the StringReplacer (to erase the characters parsed) but I keep hitting resources limitations, mainly memory.
I am running it on a 64bit OS machine with 16Gb RAM, but apparently that is not enough.
Has anybody done something similar and can share some insights on how to keep the memory eating capacity of FME down to the minimum?
Is there a better way to parse the file, than standard FME transformers?
Any help is appreciated.
Itay