I know there are already posts about this, but couldn't find much info about it.
I have a column in csv with multiple fields and values in the same column:
col1{ "21" : 80.0, "81" : null, "21" : 100.0, "21" : 60.0 }
{ "21" : 60.0, "21" : 80.0, "81" : null, "21" : 80.0, "21" : 100.0, "21" : 100.0, "21" : 60.0 }
Representation-
21- max speed
81- max weight
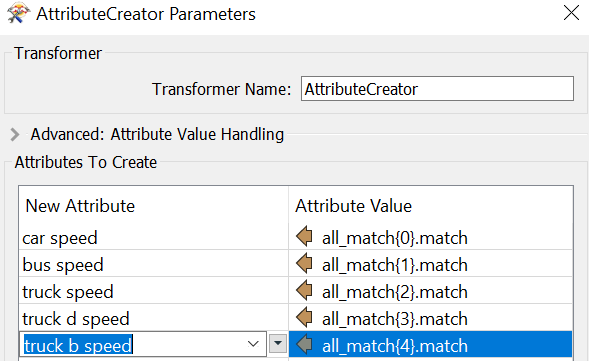
The occurrence of fields:1st time- Car, 2nd time- Bus, 3rd time-Truck
Max Speed (Car)Max Weight(Car)
Max Speed (Bus)
Max Speed (Truck)
Max Speed(D Truck)
Max Speed (B Truck)
80
null
100
60
null
null
60
null
80
100
100
100
Attaching the csv.
I am able to use AttribuleSplitter, SubstringExtractor and putting them in fields, but the values are not in uniformity. Any suggestions?
Thanks in advance.