

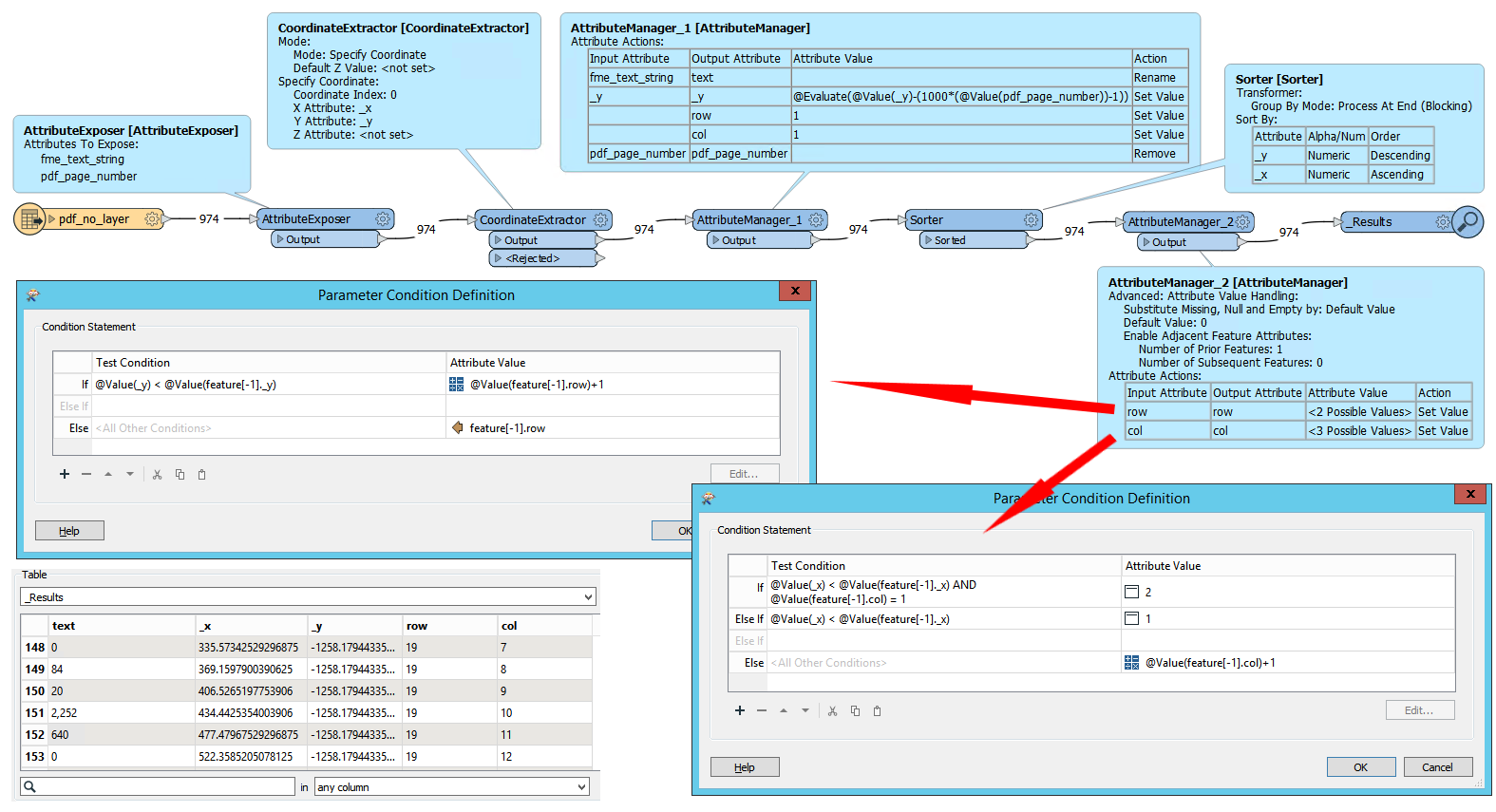
Anyone help me out to extarct the data from this pdf please

Question
Extract the Data from pDF





Login to the community
No account yet? Create an account
An FME Account is required to contribute
LoginEnter your E-mail address. We'll send you an e-mail with instructions to reset your password.