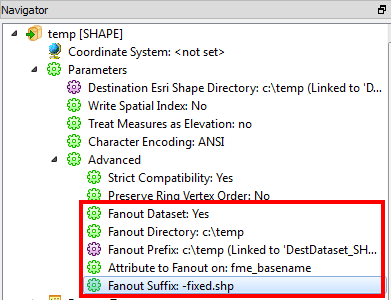
I am using Dynamic Schema to translate a large number of shapefiles from one coordinate system to another, but keeping the same schema.
I am able to do this successfully however I cannot work out how to suffix each translated shapefile so as to differentiate the translated files from the non-translated files.
I have tried setting the Fanout Parameter to Yes, but it only suffixes the folder with the translated files, not the actual shapefiles themselves.
Does anyone know how to do this?
Thankyou