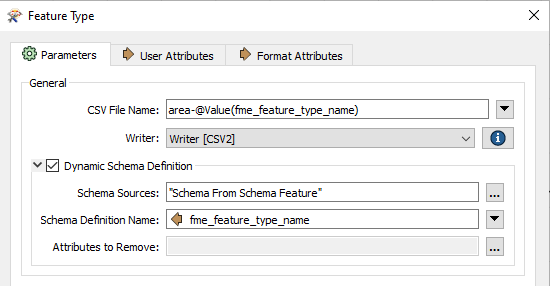
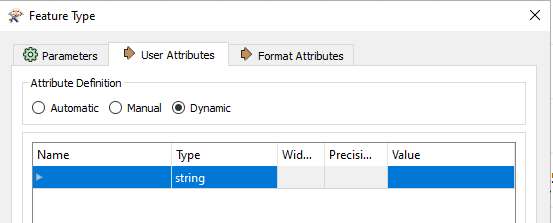
I have a huge dataset and I want to make writers based on type. Some types have only 1 samples, some have 100, and I would need to remove all empty sample-columns from all writers. There are over 100 types, so manual work is out of question.
I have tried to use NullAttributeMapper and set all values to missing, but how to drop them before writer?


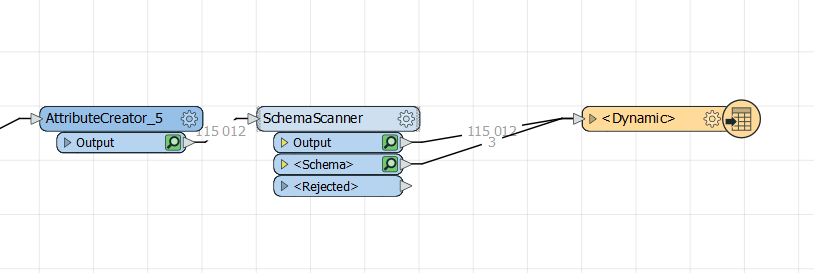 ScemaScanner
ScemaScanner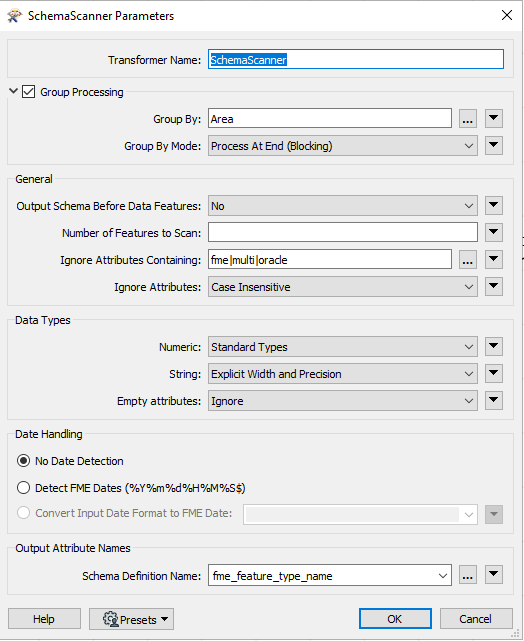 CSV Writer:
CSV Writer: