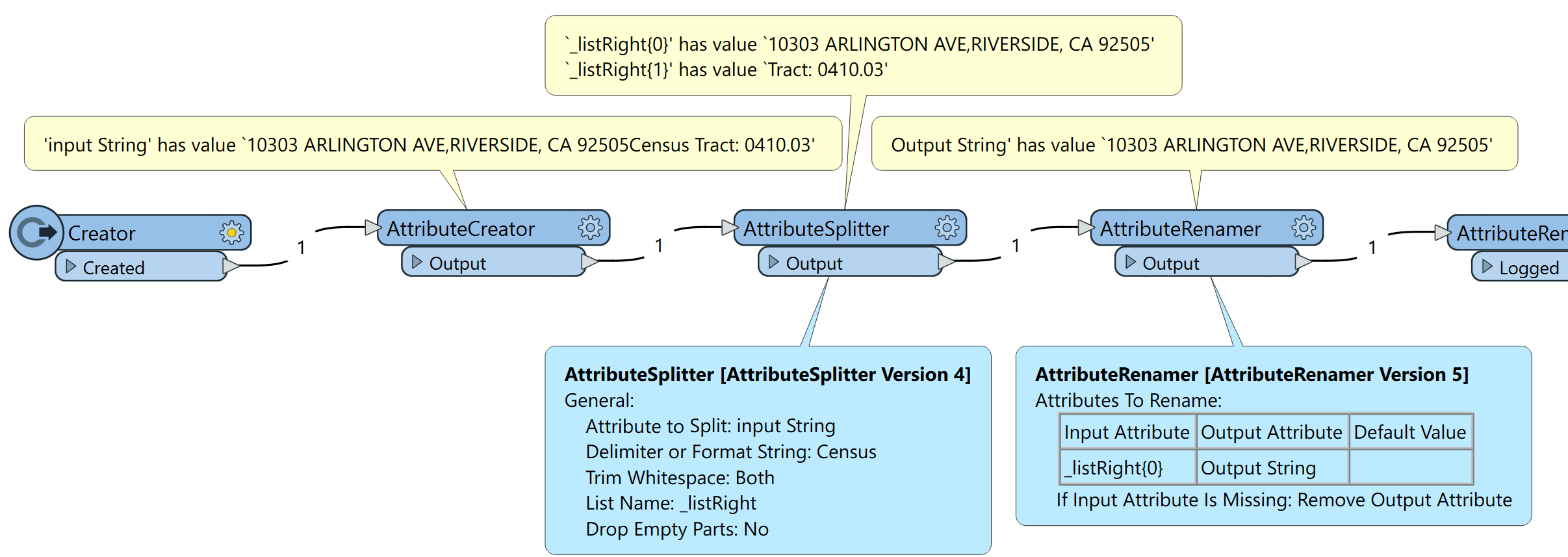
input String is :
10303 ARLINGTON AVE,RIVERSIDE, CA 92505Census Tract: 0410.03
Output String needs to be:
10303 ARLINGTON AVE,RIVERSIDE, CA 92505
I'm using the StringSearcher with the follow RegEx
([A-Za-z0-9]+( [A-Za-z0-9]+)+),[A-Za-z]+, CA \\s\\d\\d\\d\\d\\d
The result I'm getting is empty.



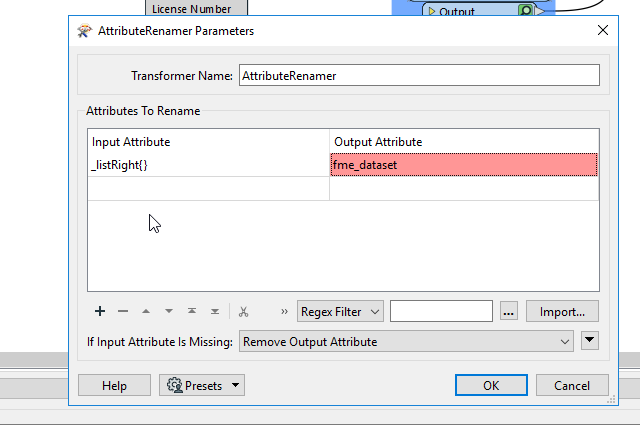 I do see a regex filter that I do have for the front characters I want to keep
I do see a regex filter that I do have for the front characters I want to keep