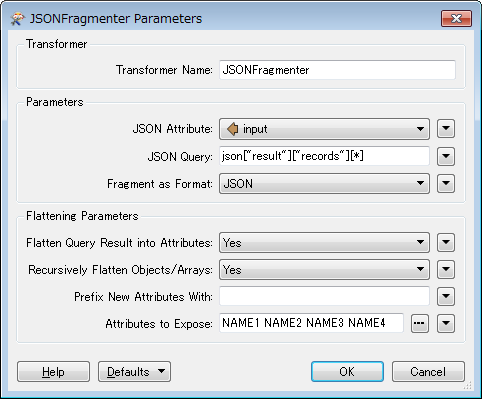
I'm extracting data nightly from JSON services of which have no validation. These datasets have over 100 columns. Is there way to import a schema into the attribute validator so for every column it would test data type and max length? It would take forever to test data type, structure and max length for every column in every dataset, but my fme processes keep failing.

Question
Validating attributes against existing schema
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.