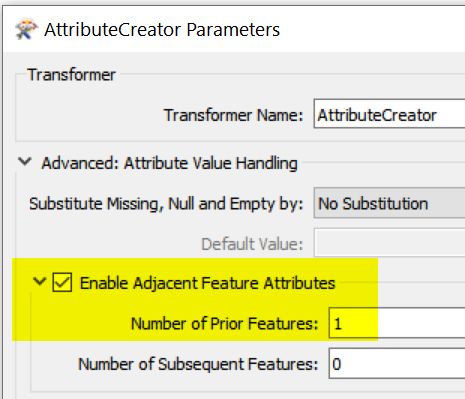
I have a block of text separated by newline characters, e.g:
Some Text
Some More Text
Even More Text
PERIOD: 01/01/1990 TO 12/12/2020
What I'm attempting to do using regex is grab the entire line of text preceding the row beginning with PERIOD (i.e. "Even More Text"). In an online regex editor, the following expression successfully returns just the line containing "Even More Text":
^.*$(?=\\nPERIOD)
However, when I attempt to do the same in FME, it returns all lines above PERIOD. It seems as though in online editors the . includes all characters except newlines, whereas in FME it includes them? Is there a way to adjust multiline regex flags (or some other workaround) in FME to get the desired output?