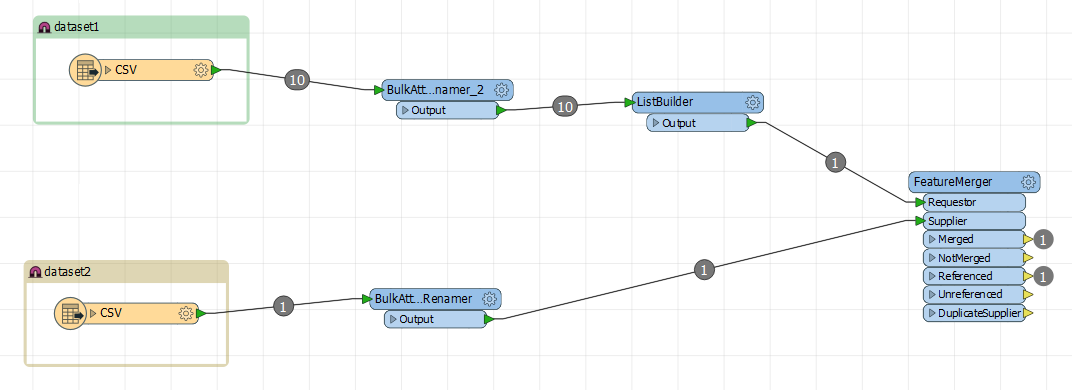
How can I use the FuzzyStringComparer on 2 lists?
For instance:
Table1_AttributeABC COMPANYDEF COMPANYTable2_AttributeABC INCDEFMy intention is to generate a table as follows:
Table1_AttributeTable2_AttributeratioABC COMPANYABC INC0.55DEF COMPANYDEF0.43Using a post from @takashi, I merged the 2 datasets by using the FeatureMerger transformer and a constant of 1. I then generate a list using the FeatureMerger transformer and called it dataset2.
I then try to use the FuzzyStringComparer, but it asks me to pick a single attribute. If I choose the dataset2.list{}, it wants a single element in that list, and doesn't seem to be able to iterate through the list.
Any help would be appreciated!