Hi,
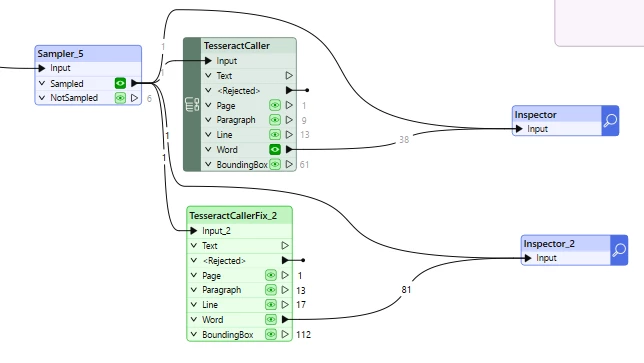
The TesseractCaller appears to be partially broken at the moment. It sometimes doesn’t return all words from the OCR process and the results aren’t transformed correctly to fit on the page. I suspect that this is the results from Tesseract having been updated since the release of the transformer. See the images below as documentation. Where the existing TesseractCaller produces 38 word results from my input image and the fix produces 81. (This difference is the result of a listexploder rejecting features not containing a list, so nothing has been changed about how FME interacts with Tesseract) The results are also correctly flipped and scaled in FME to match the input image. I have supplied the fixed transformer as a zip to this post.