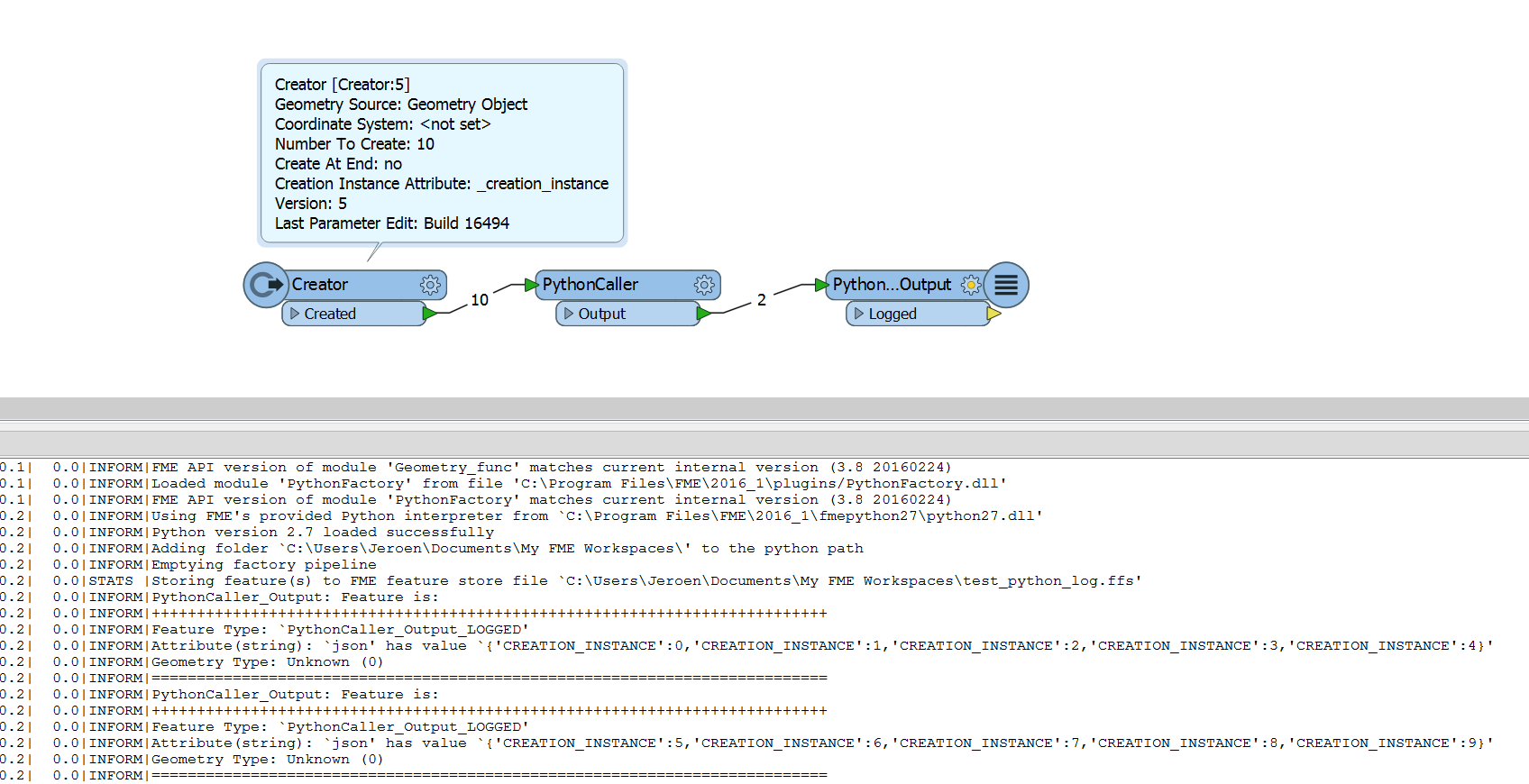
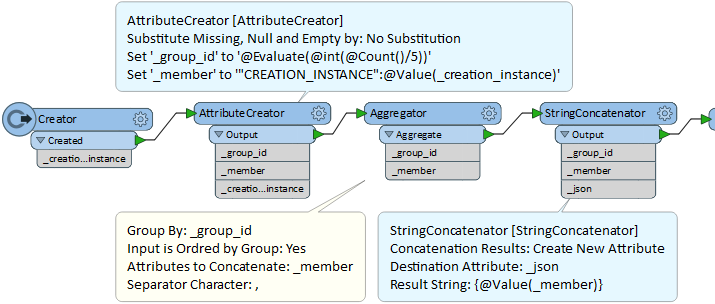
I would like to be able to separate a feature into smaller chunks and process them 1 by 1
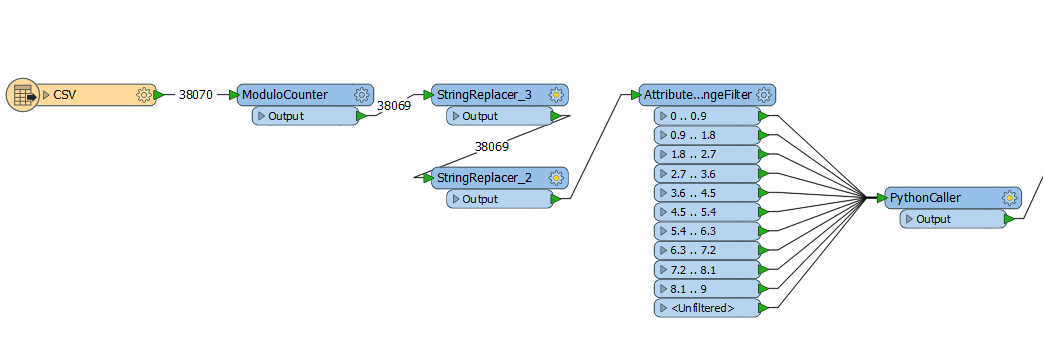
I have managed to use ModuloCounter to separate the feature but I am unsure how to get the rest of the workspace to process the broken up features 1 by 1.
If I send all the output into pythonCaller they are executed together at the same time.
Any ideas?