


When I attempted to upgrade to StringPairReplacer, Show Changes displays:
StringPairReplacer Version 2 replaced by StringReplacer Version 6
StringReplacer Change Log, version 6
- Added multi-attribute string replace support.
My Replacement Pairs in StringPairReplacer v2 has multiple lines and quotes. This has worked great for years, and now I can’t upgrade. My first impression is that StringPairReplacer was changed so dramatically that it might have been better to leave it alone (and not replace it with StringReplacer).
Here’s what my old StringPairReplacer looked like.
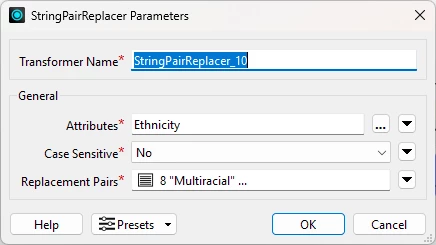
And here are my Replacement Pairs (using the Open Text Editor). I use multiple lines and quotes, and it works great.
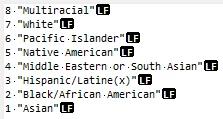
Apparently, the upgrader is not expecting multiple lines or quotes. It’s a mess.
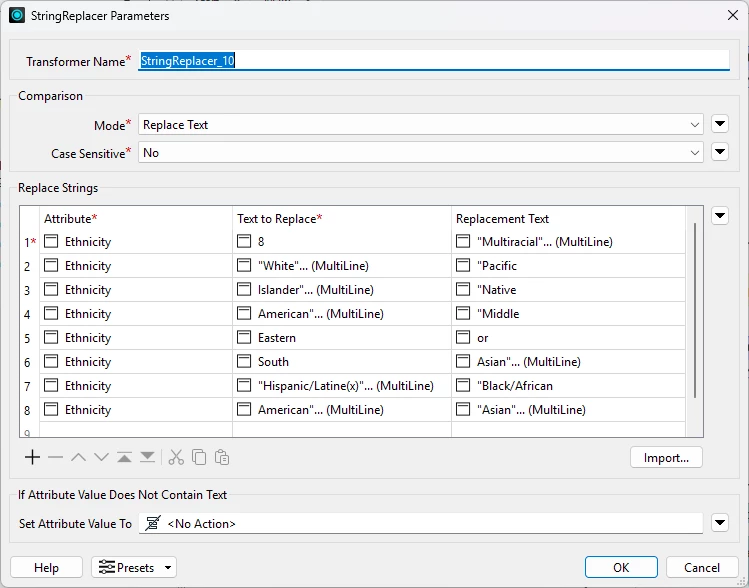
I tried creating a csv file but, I couldn’t figure out the proper format.
Finally, I removed the quotes (replacing spaces with underscores) and put it on a single line.

Now, the upgrade works.
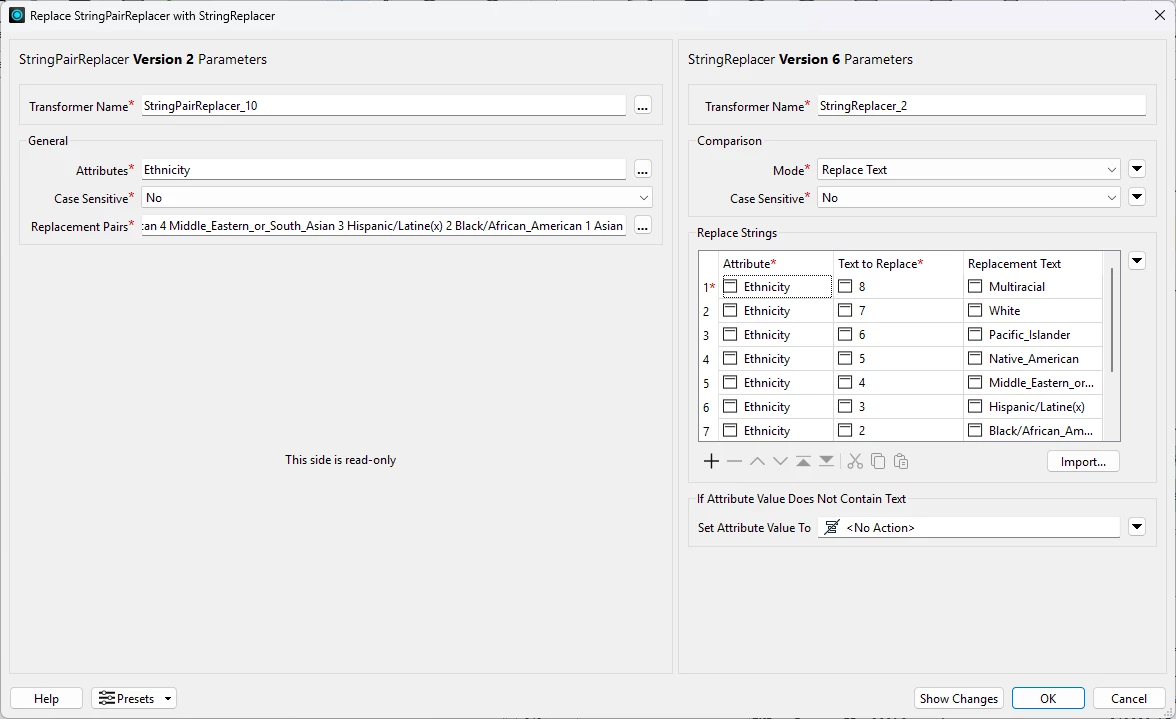
I wouldn’t call this success. It will be time consuming to fix all my StringPairReplacer transformers in all my workspaces. This is kind of a nightmare. The first time I upgraded StringPairReplacer I didn’t notice the upgrade had failed until I noticed that the output was wrong. I have public facing data and this is challenging.
Does anyone have any thoughts or suggestions? Should the upgrader have broken my StringPairReplacer transformers? Is this a bug?






