In a SQLExecuter, I'm using a SELECT statement where PKey IN (@Value(ID)
I'm getting the oracle error:ORA-01795: maximum number of expressions in a list is 1000,as the number of of concatenated ID's passing the query is exceeding the 1000 limit.
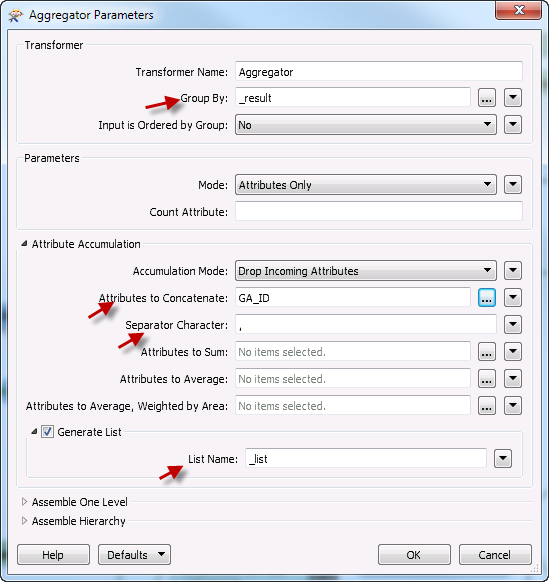
so I used an Aggregator and a Smapler trying to split the stream of data entering the SQLExecuter (every 1000 features), but that didn't work as I wish.. (pass a pack of every 1000 features to SQLEXECUTER)
Any idea?