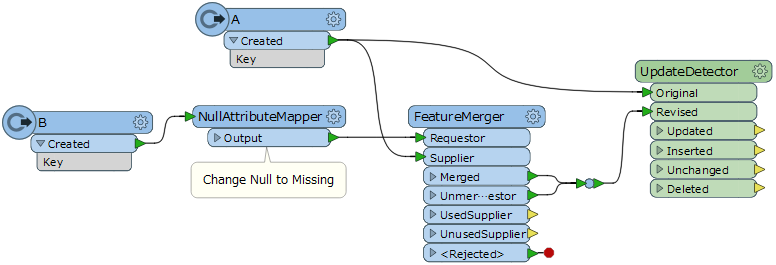
I am using the UpdateDetector to update GDB_A.
GDB_A is entering the UpdateDetector through the Original Port.
GDB_B is an updated version of the same data and enters the UpdateDecector through the Revised Port.
GDB_B more often than not includes all of GDB_A plus some new features, these correctly exit through the Insert Port.
GDB_A has had many changes made to its attributes since the last update (basically attribute data has been entered in manually replacing Null values with more useful data)
As these manually added values do not exist in GDB_B, any rows that have been manually adjusted in GDB_A exit the UpdateDetector through the Update Port, with the manually added data in GDB_A having been replaced with the Null value from GDB_B.
I am looking for an elegant way to prioritize any value over a null value for every attribute, regardless of whether the value is sourced from the Original (GDB_A) or the Revised (GDB_B) dataset. But also if there is a true update; ie both GDB_A and GDB_B have values and they differ, then it should exit via the Update Port with the GDB_B value.
Thanks in advance.