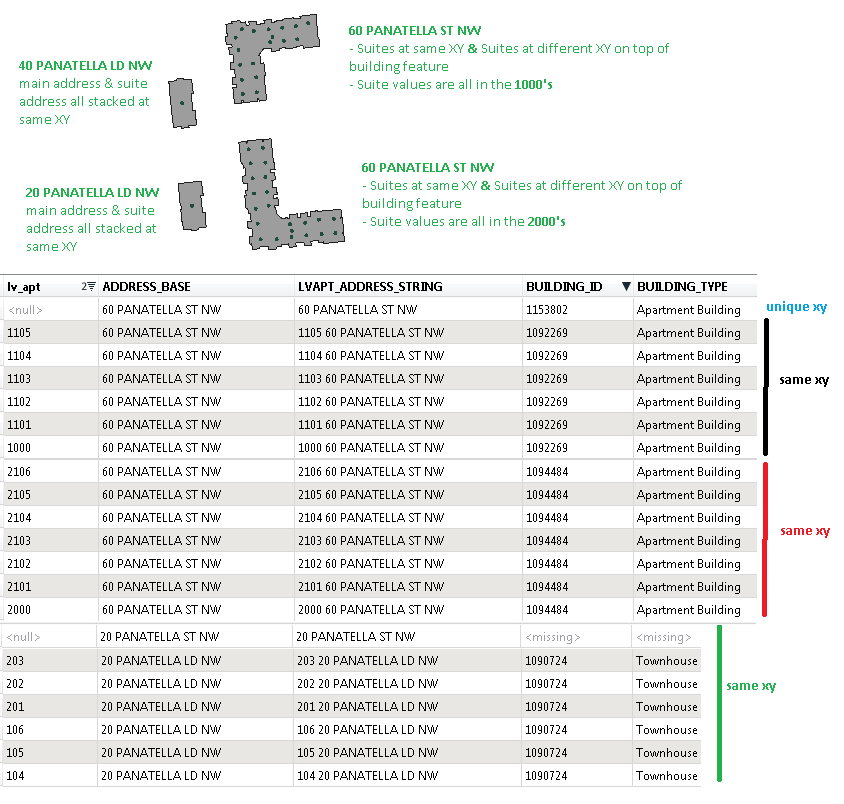
I am looking to filter out specific types of addresses from a full dataset of addresses. These addresses include points that can represent the main address (ADDRESS_BASE) (ex: 123 main street), or addresses that include a suite addresses (LVAPT_ADDRESS) (ex: #3, 123 main street).
Scenario 1: If the main address and the suite address are all stacked at the same XY, then I want to select the main address (this isn't hard)
Scenario 2: If there are groups of suite addresses with the same main address on a building but with each slightly different XYs then:
Option A: if the group with the same main address is all on one building then select the main address
Option B: if the group with the same main address is on more than one building then keep all addresses.
My brain is getting tired of running through different ways to make these different kinds of selections/filters. I have tried the Matcher because it includes a MATCH_ID value, but the MATCHER seems to require the points need to be exactly at the same XY to be considered a match. So, I need to be able to have a tolerance. So, then I used the PointOnPointOverlayer (POPO) as it has a tolerance option, but this doesn't have a MATCH_ID, it has a count of how many were found to be on top of each other.
I have probably just been staring at this for too long and would really appreciate some outside insight.
I hope you are all doing well in these unique times.
Here is a snippet of data: