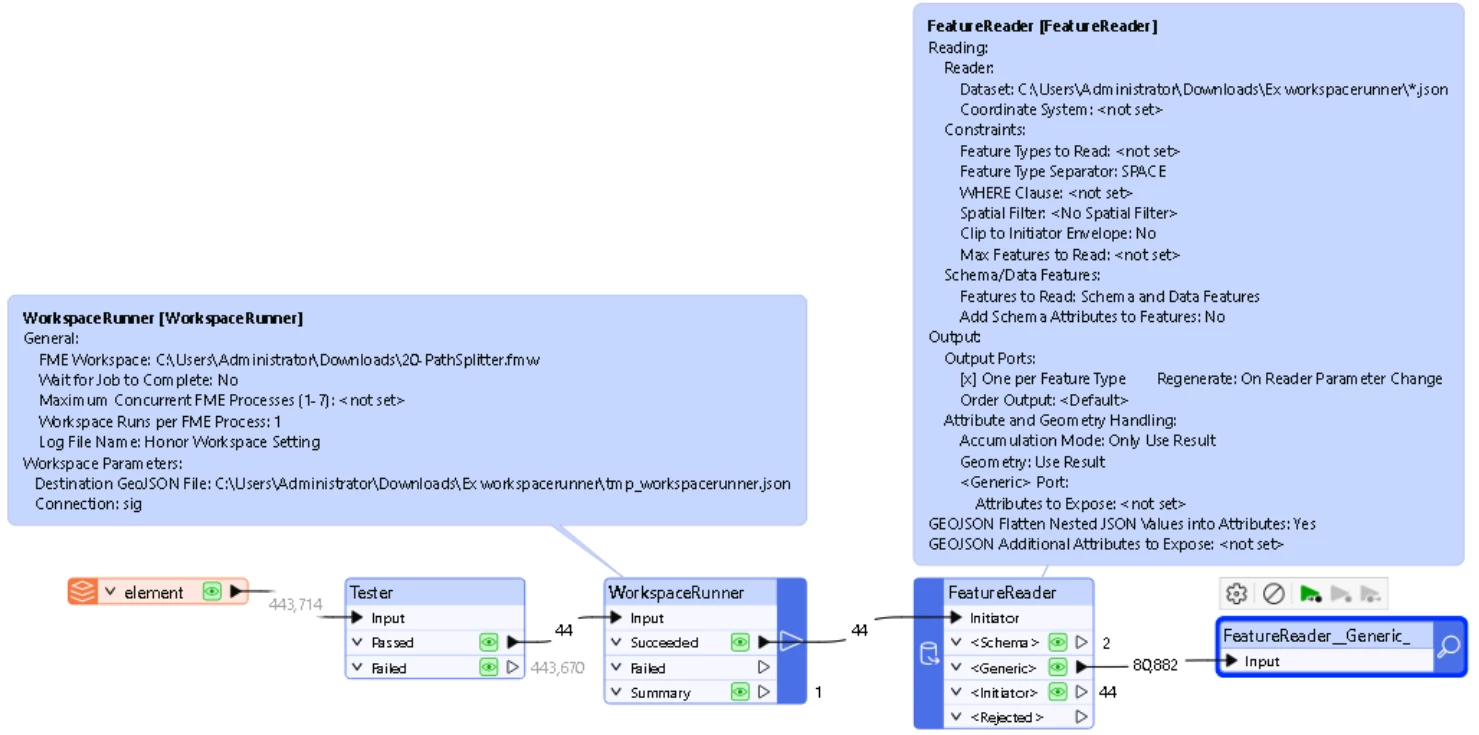
I would like to use the WorskspaceRunner for optimize the performances of my treatments, but I’ve difficulties to configure them. More precisely, I don’t how can I configure the reader/writer of child workbench, whereas I try to do same things like this tutorial.
In this example, I try to have in input, a filter on limited objects, but in output I’ve all objects.
This is my main workbench :
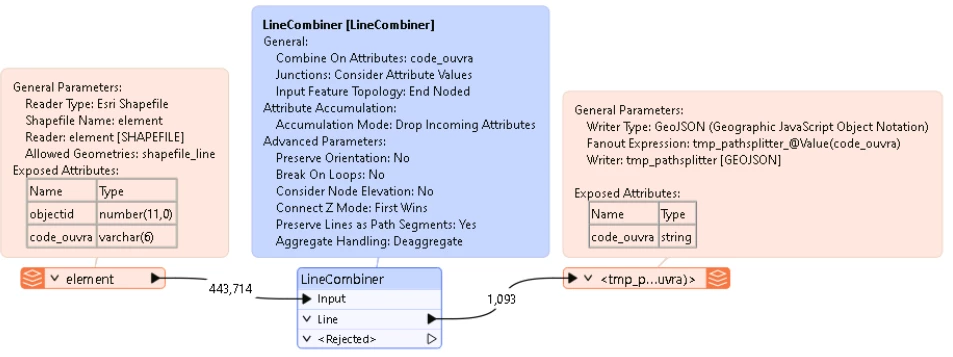
And this is my child workbench :
How can I can I do ?
Thank you very muche.
Best answer by redgeographics
Okay, so is there a logical way that you can divide those lines? Since you’re grouping on code_ouvra in your LineCombiner that is probably best, do you know how many unique values there are for that?
Assuming it’s not too many:
Change your child workspace to filter out a single value for code_ouvra and then use the LineCombiner on those. Make that value a User Parameter
Change your parent workspace to have a Sampler after reading your data, set that to group by code_ouvra and only pass the first feature. Essentially this gives you all the unique values for code_ouvra.
Have the WorkspaceRunner run your child worksplace and plug the code_ouvra attribute into that User Parameter.
You should end up with one file per code_ouvra, so you’ll need to combine them in the end, I think your FeatureReader does that.
There’s still a bit too much overhead for my liking: the child workspace does read all of the features before selecting them, so this may not be an improvement.
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
You’ll need to have a user parameter in your child workspace that you can use to limit the amount of data it’s going to process, then fill that parameter dynamically through the WorkspaceRunner.
Without knowing a bit more about what you’re trying to do and how you could potentially divide the data up it’ll be hard to give you more detailed advice.
Okay, so is there a logical way that you can divide those lines? Since you’re grouping on code_ouvra in your LineCombiner that is probably best, do you know how many unique values there are for that?
Assuming it’s not too many:
Change your child workspace to filter out a single value for code_ouvra and then use the LineCombiner on those. Make that value a User Parameter
Change your parent workspace to have a Sampler after reading your data, set that to group by code_ouvra and only pass the first feature. Essentially this gives you all the unique values for code_ouvra.
Have the WorkspaceRunner run your child worksplace and plug the code_ouvra attribute into that User Parameter.
You should end up with one file per code_ouvra, so you’ll need to combine them in the end, I think your FeatureReader does that.
There’s still a bit too much overhead for my liking: the child workspace does read all of the features before selecting them, so this may not be an improvement.