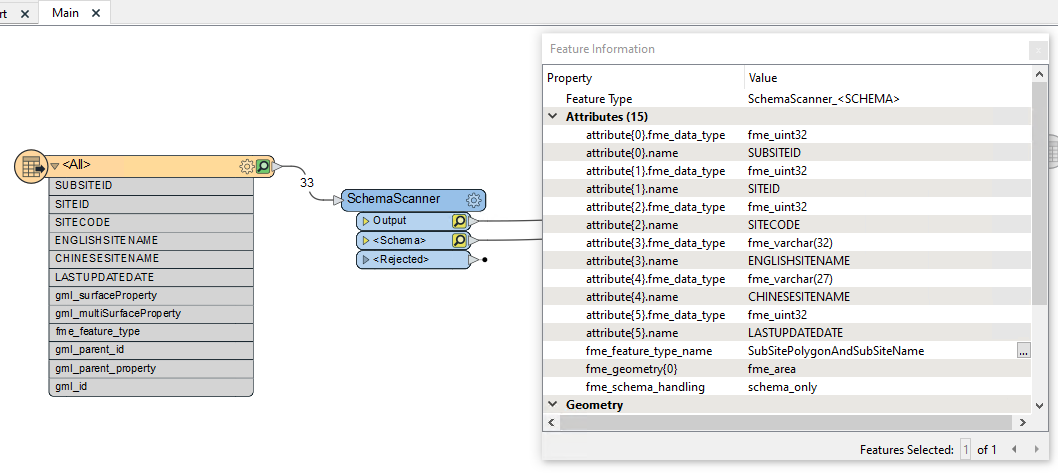
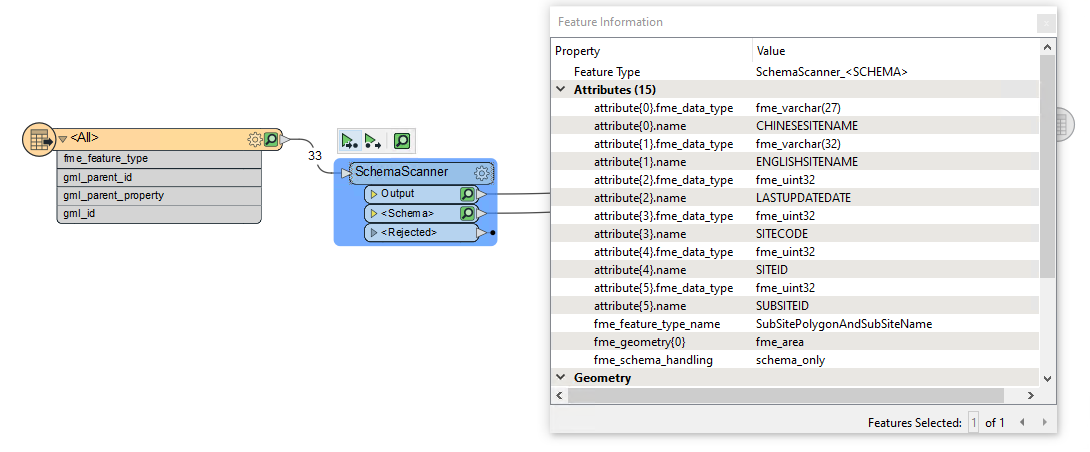
In FME version 2023.1. We can keep the attribute field order after schema scanner for most of dataset.
But for the attached dataset, we can't keep the attribute field order after schema scanner.
Is any problem in my dataset?
The fmw is attached also
Thanks