Hi there,
I have a database with a series of different street names from all over the world.
In some regions that use multiple alphabets in their local languages, I have mixes of this. I.e. one name in Latin, and another in Thai, Arabic, Cyrillic, etc.
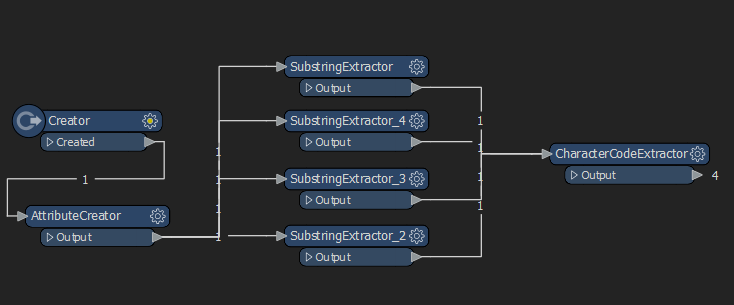
What I'd like to do is pretty simply on paper: Look at each string in my list and determine what the alphabet used is. As simple as a new attribute indicating the language as "Latin" or "Japanese", and so on.
I've tried the CharacterCodeExtractor, but checking only the first character is not always useful, especially in cases like greek where some of the letters exist in both Greek and Latin alphabets.
Any ideas on this?
Thanks a lot!