I'm still a newbe to FME considering below.
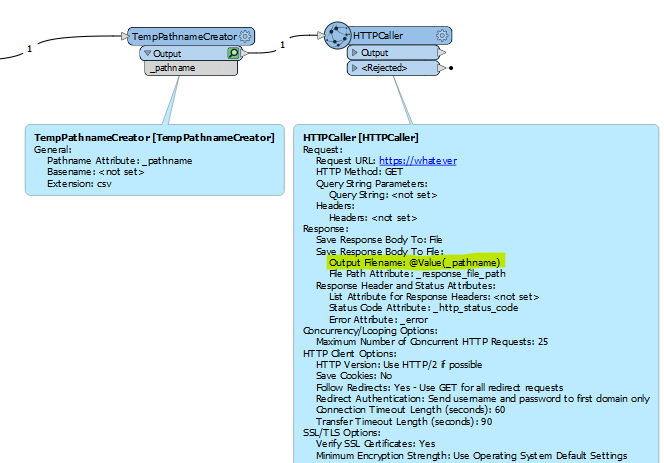
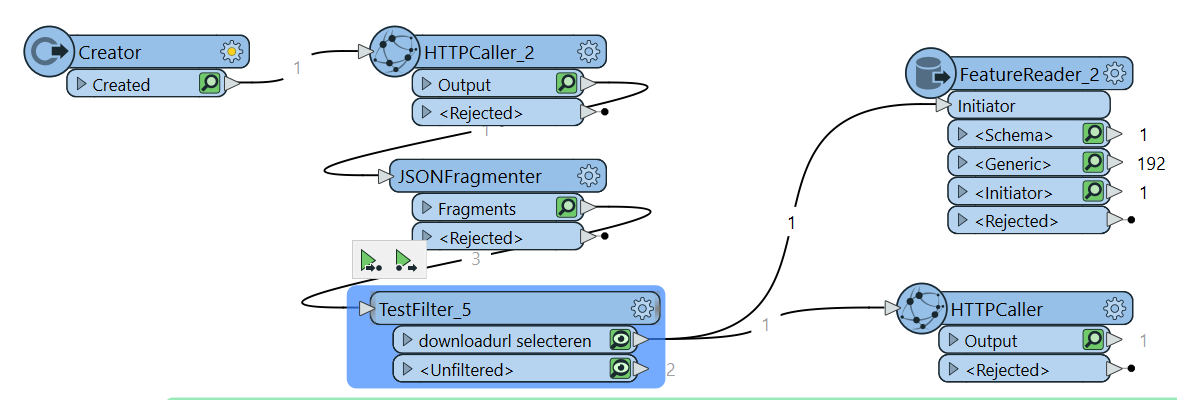
I'm trying to query open data from the Dutch https://public.ep-online.nl/api/v4/Mutatiebestand/DownloadInfo?fileType=csv (API-key required, available from https://epbdwebservices.rvo.nl/) to get the data from a csv-file. HttpCaller works, url obtained with JSONFragmenter (attributes to expose: 'downloadUrl’)+testfilter (to get the actual url).
However, I can't seem to use this url in an FeatureReader or further HTTPCaller to actually get the data itself from the csv-file. Copying the url (contains a token valid only one time) does download the file from a browser as a zip-file, but how can this be done in FME?
I tried to look at https://public.ep-online.nl/swagger/index.html but couldn't make anything out of it due to lack of technical knowhow.
Any ideas?
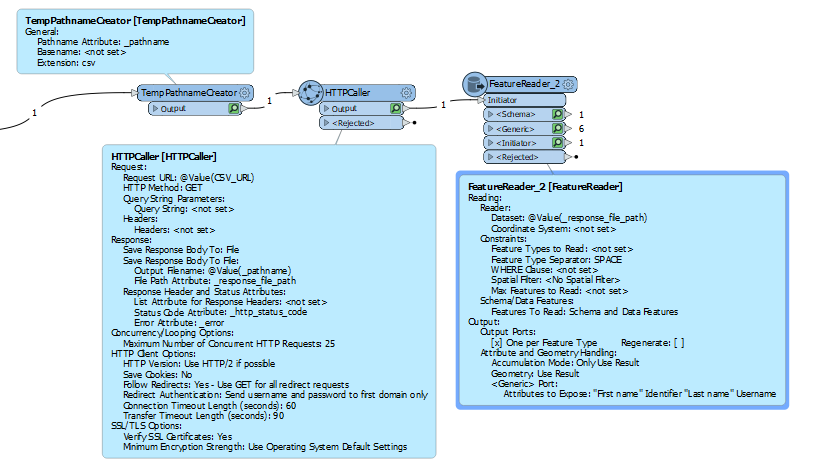
Setup as of now:
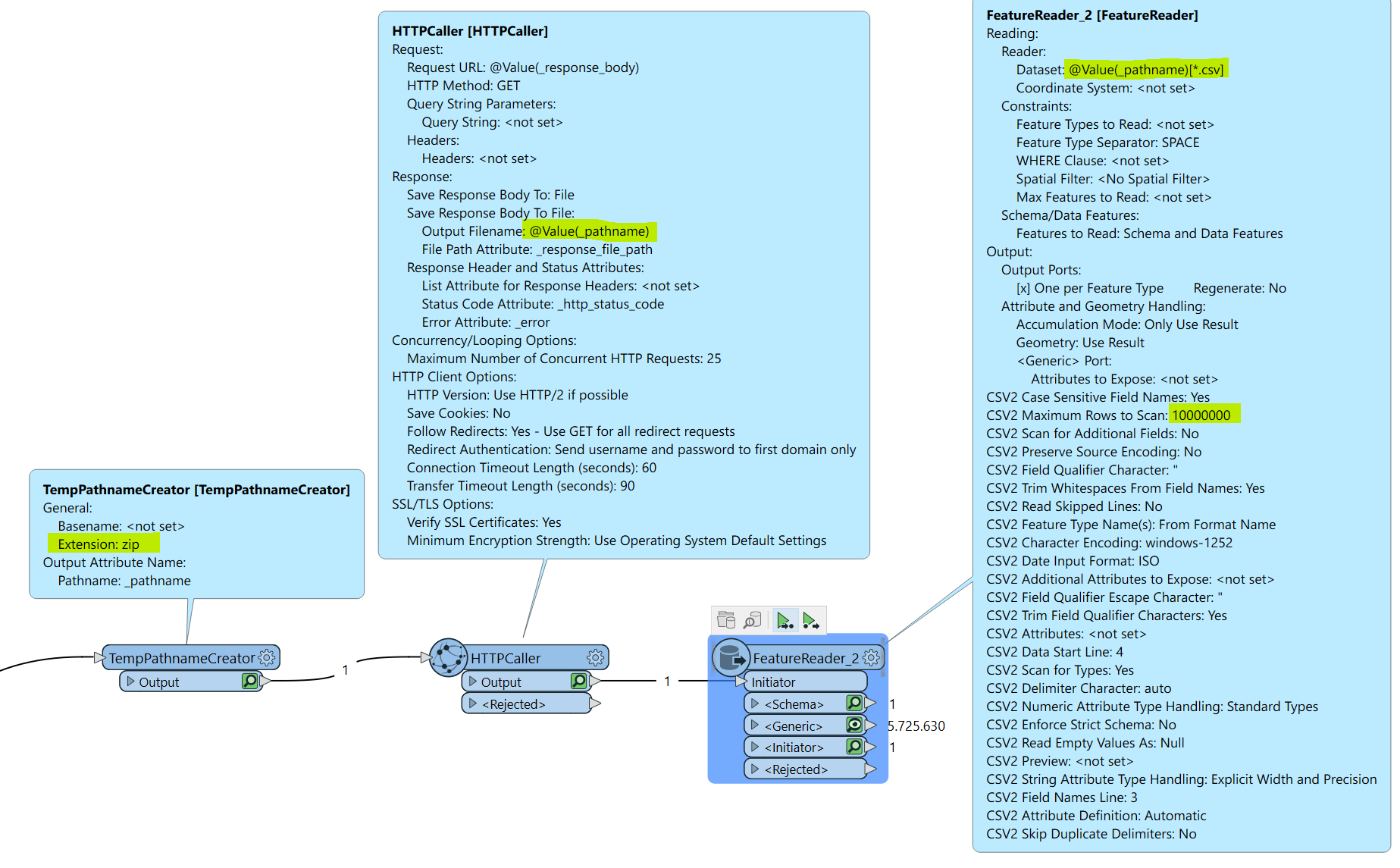
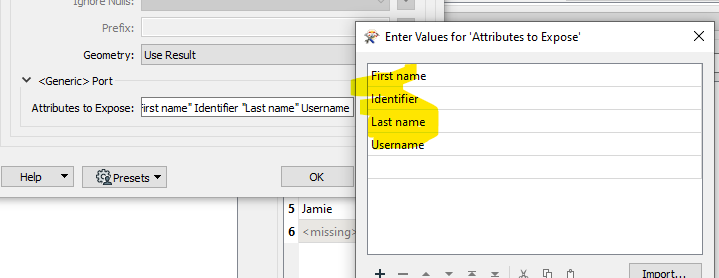
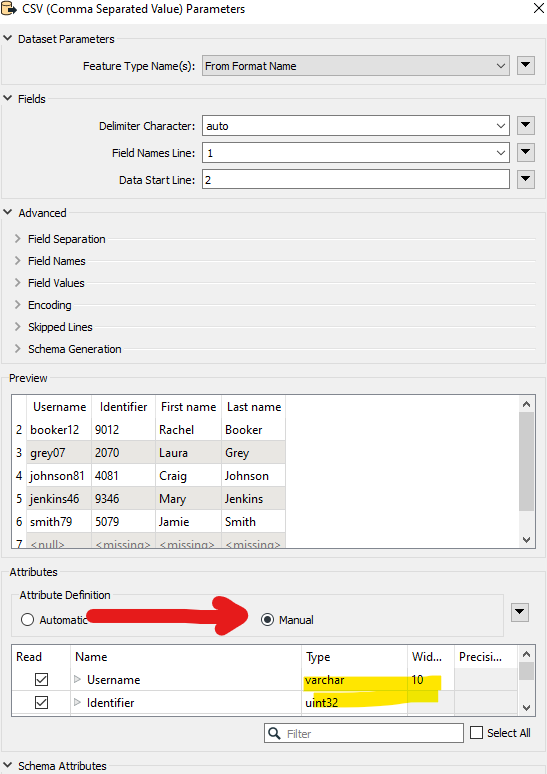
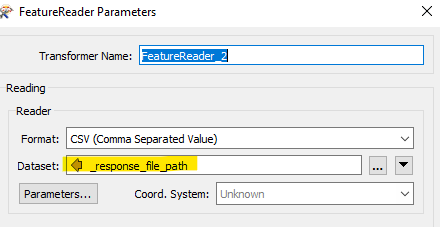
FeatureReader tried below (the response_body solely contains the url):
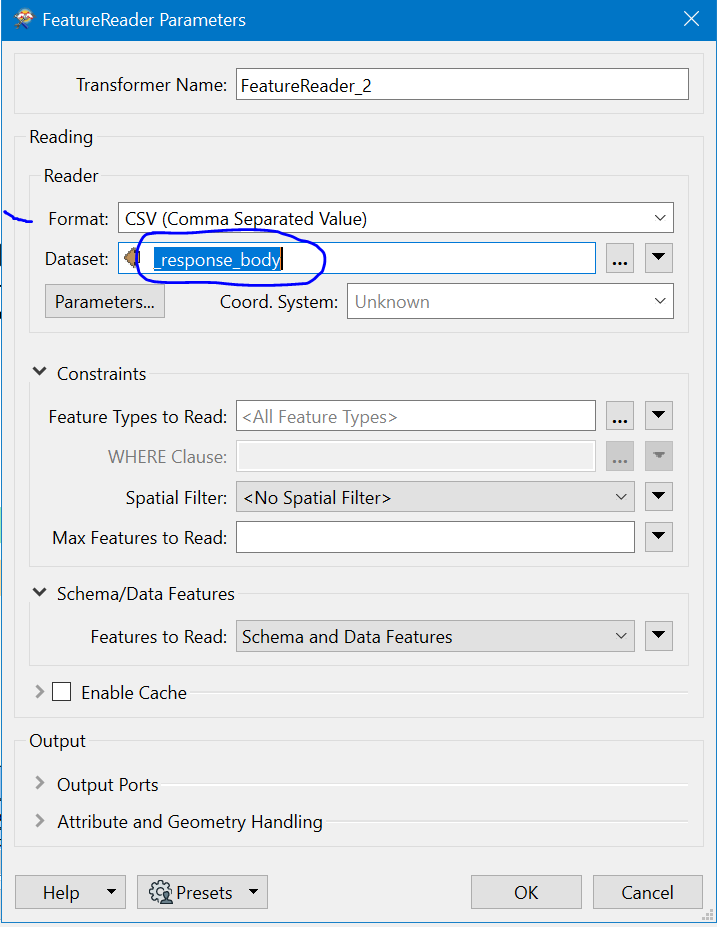
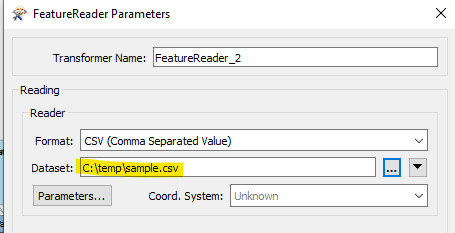
Also tried '@Value(_response_body)[*.csv]’ for parameter dataset, but also to no avail.
Another try with a second HTTPCaller:
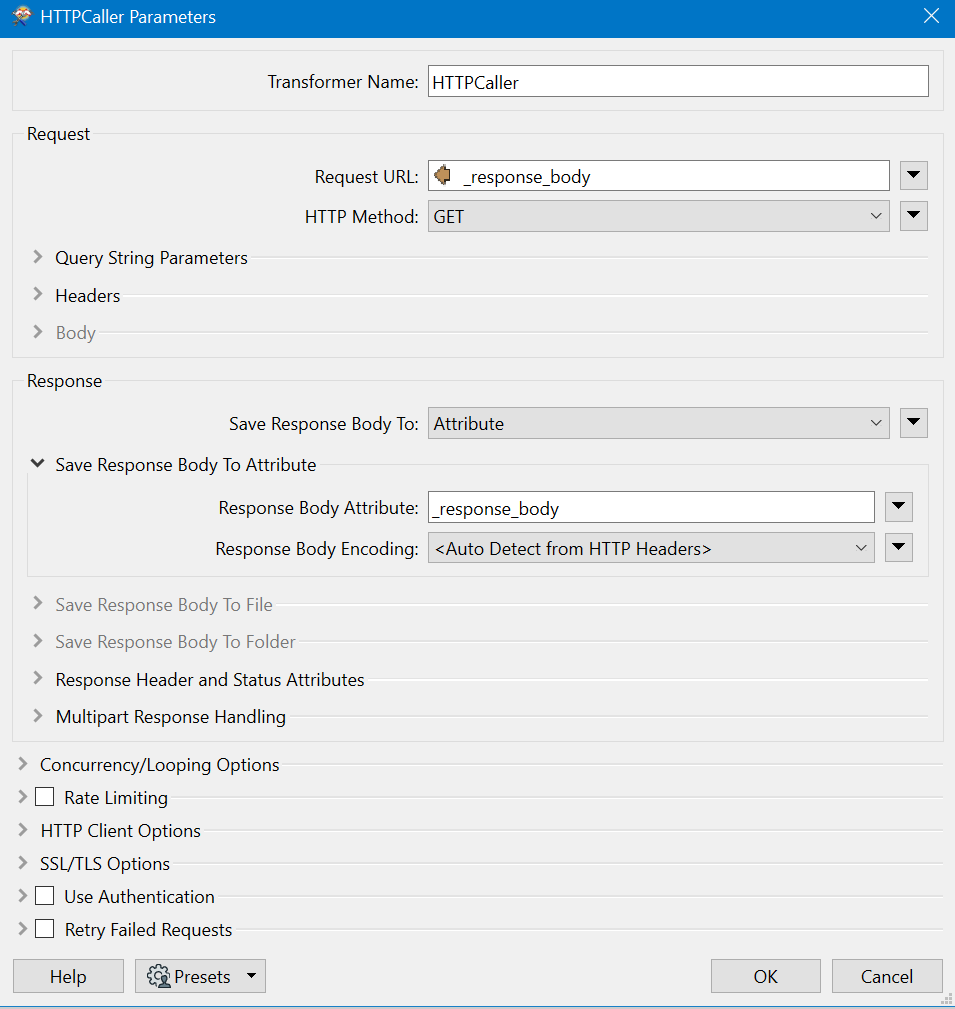
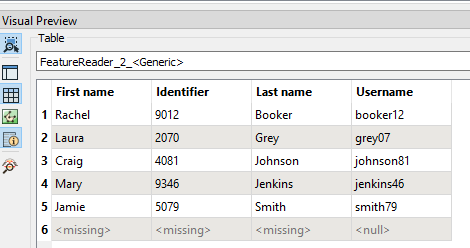
Both don't return the zip of csv file containing over 1,000,000 items.