In a related topic I’ve asked about api’s and JWT authorization:
The currently only way is to do this via python. I’ve got myself a script that I call via a systemcaller that runs the python script in a conda environment (not keen on installing extra python stuff in the FME locations). This works as I can fetch my bearer token to do api calls.
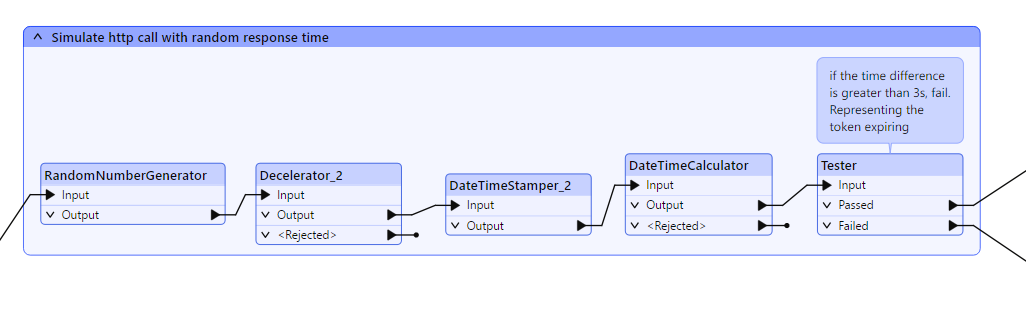
However there is an expiration time on the bearer token (1hour).
So now I’m wondering how to tackle this the best way:
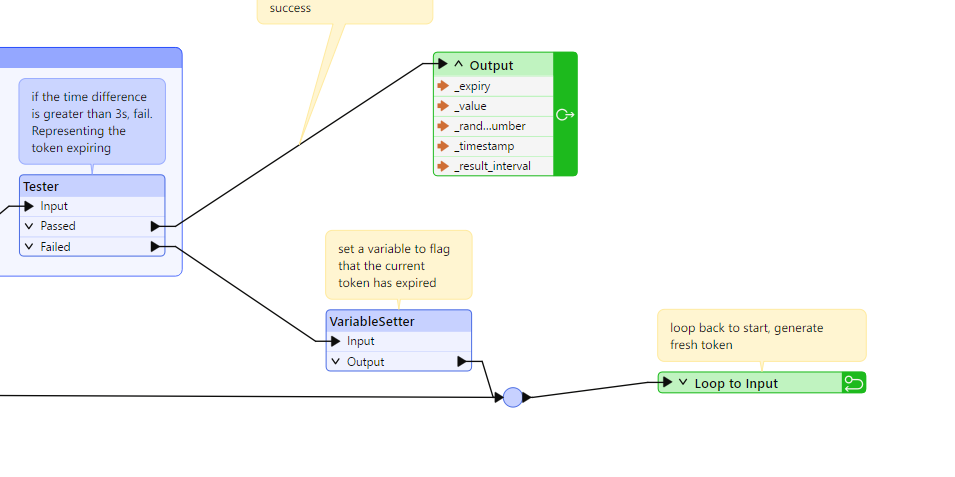
I want to do several http calls in parallel (default 25) but if I’m using the token voor 3500 seconds, I want to call my CT for getting a new bearer token. Any not processed calls (I need to make 3k+) should now use the new token. If I again come to this 3500 seconds another refers etc.
So what would be a good way to achieve this kind of looping? As the http caller has a limitation that if there is a loop port, multi threading should be set to 1, beating my purpose.
I also don’t want to duplicate transformers, because I don’t know how many iterations I would need might be 1 or 5 …
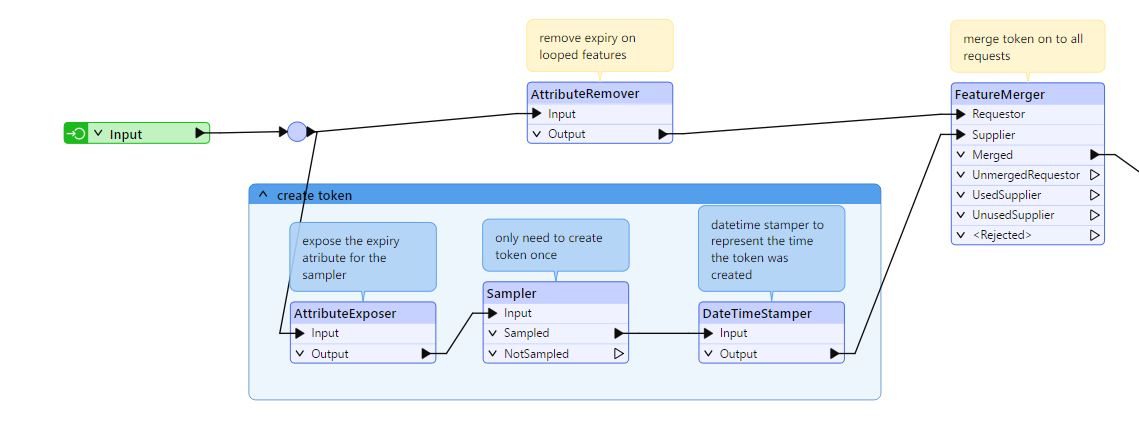
So currently I do 1 api call to know how many features I need to get ex 373702, the limit per call is 100 => 3738 calls need to be made, so I clone my 1 record 3738 times and do the http calls in parallel .
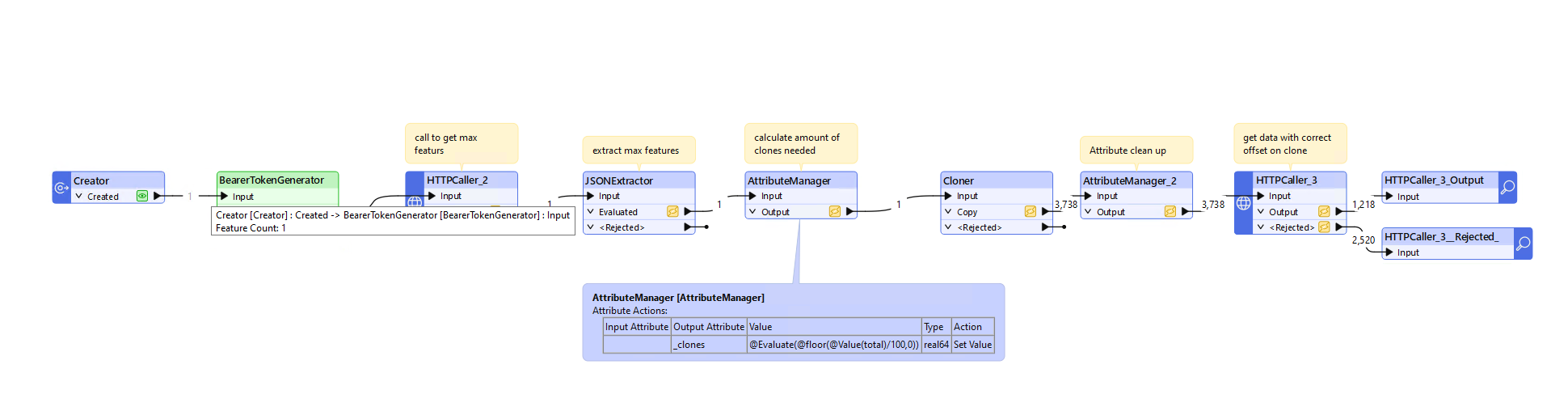
Ideally everything that is rejected with 401 error (like above screenshot), should be looped through the BearerTokenGenerator again and reprocessed in the http caller. However no multithreading is possible
Anyone some ideas about how to handle this?
One thought that I had was to create groups of 500 or 1k calls and put those also in a CT with a group by clause. Per group (of 1K so 4 groups in my example) I would get a token, would be able to do parallel threads (and probably even parallelization on the CT itself, if the other server can handle that).
But it still seems dirty as I don’t know if 500 or 1k per group would be ok or not.
So anyone any other ideas for this?