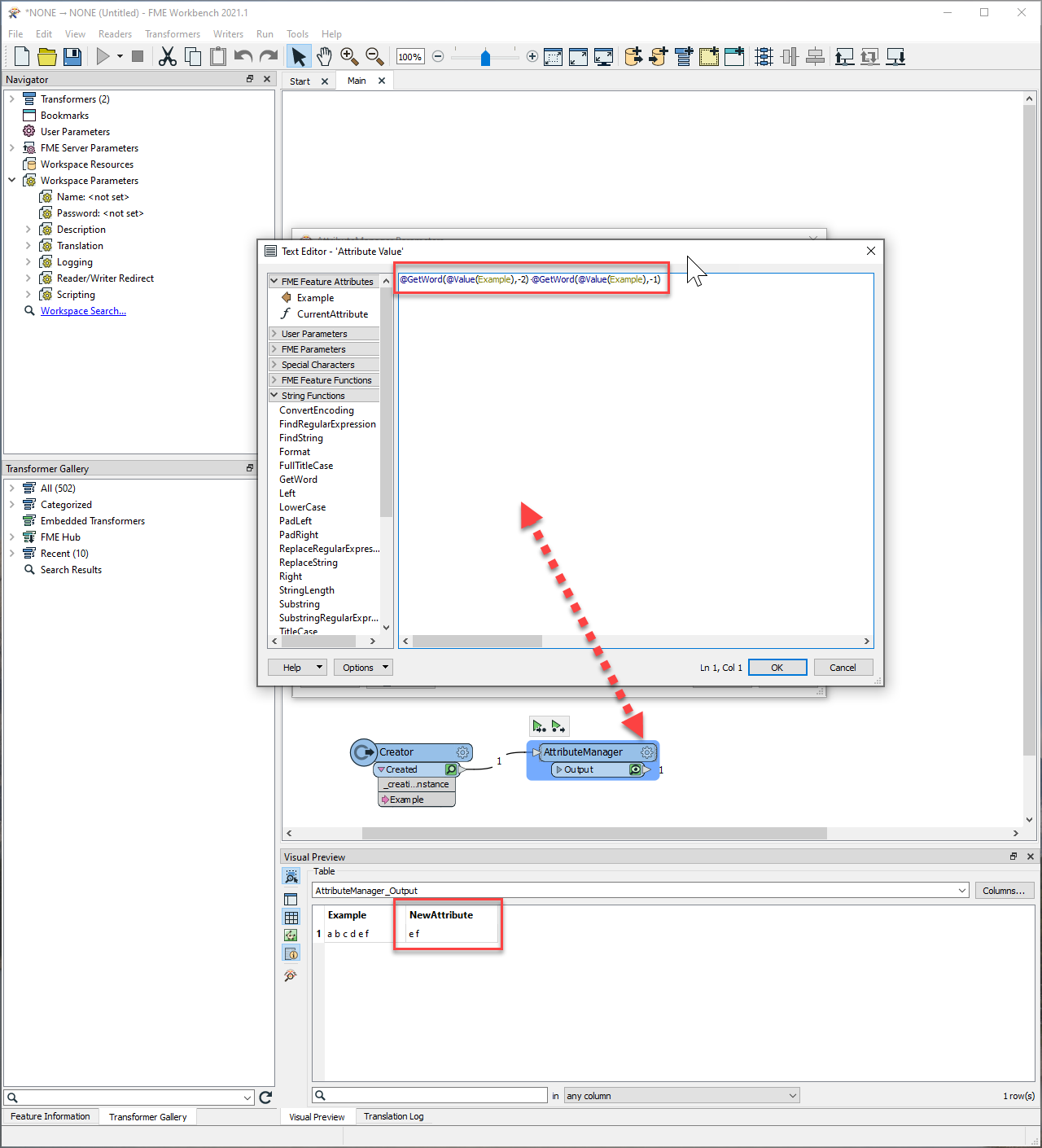
Hello Community,
I am trying to extract values of attributes in a table that is in a HTML page.
Actually the table is updated every 20 minutes or so on this URL:
https://www.hydrodaten.admin.ch/fr/2174.html
The table looks like this:
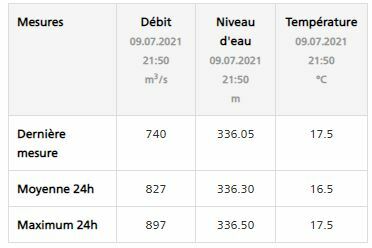 I have tried to use a HTML Table reader but unfortunately the attributes names contain also a date / time and they are changing all the time, so if I extract it at regular intervals, it doesnt work anymore as the field name will have changed in between:
I have tried to use a HTML Table reader but unfortunately the attributes names contain also a date / time and they are changing all the time, so if I extract it at regular intervals, it doesnt work anymore as the field name will have changed in between:

Then I have tried the Http Caller + HTML Extractor but I can't figure out which CSS Selector I should use to extract the values of the table.
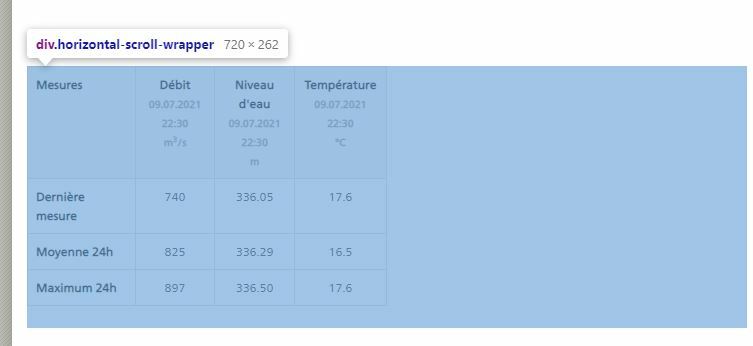
 Here is the HTML part of the webpage that contains the information I am looking for:
Here is the HTML part of the webpage that contains the information I am looking for:
<div class="horizontal-scroll-wrapper">
<table class="table table-bordered table-narrow">
<thead>
<tr>
<th width="30%" scope="col">Mesures</th>
<th class="text-center" scope="col">Débit<br><small class="text-muted">09.07.2021 20:50</small><br><small class="text-muted">m<sup>3</sup>/s</small></th>
<th class="text-center" scope="col">Niveau d'eau<br><small class="text-muted">09.07.2021 20:50</small><br><small class="text-muted">m</small></th>
<th class="text-center" scope="col">Température<br><small class="text-muted">09.07.2021 20:50</small><br><small class="text-muted">°C</small></th>
</tr>
</thead>
<tbody>
<tr>
<th scope="row">Dernière mesure</th>
<td class="text-center">744</td>
<td class="text-center">336.06</td>
<td class="text-center">17.4</td>
</tr>
I dont know how to get any further than this, it is disapointing as the information is there but I dont manage to extract it.
If some of you might have any pointers, I would be very grateful for it.
Many thanks for your time, which is indeed valuable.
Best regards.
Thomas
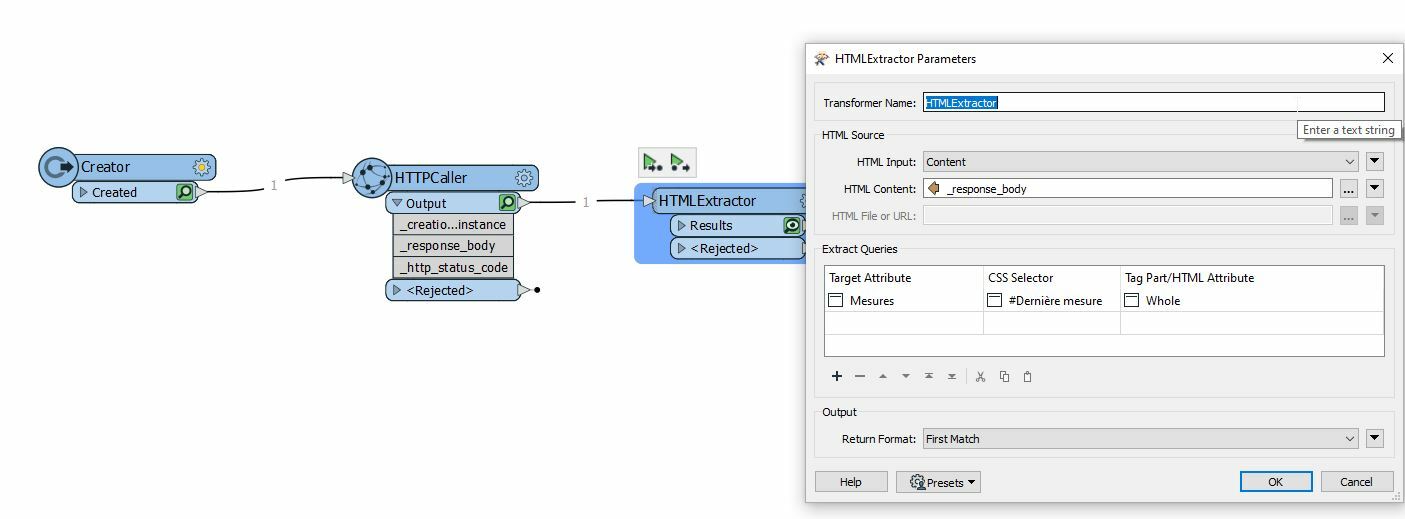
 Which I reported in the HTML Extractor:
Which I reported in the HTML Extractor: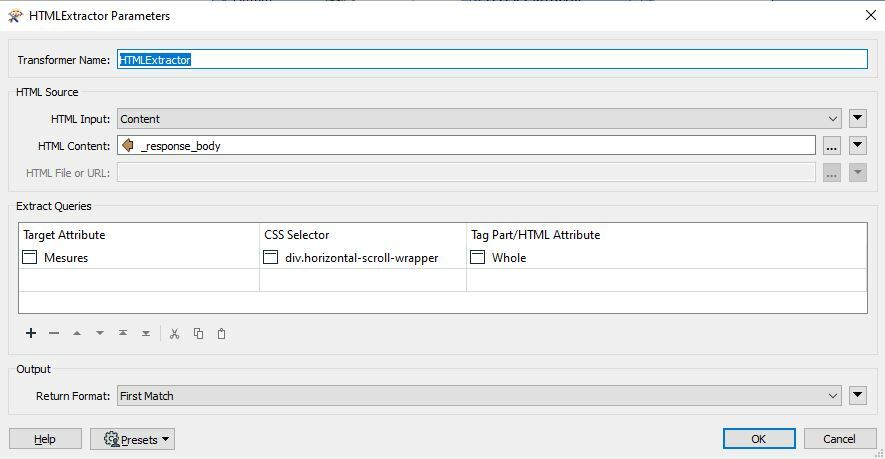 Then it gave me the table extraction as follows in an attribute:
Then it gave me the table extraction as follows in an attribute: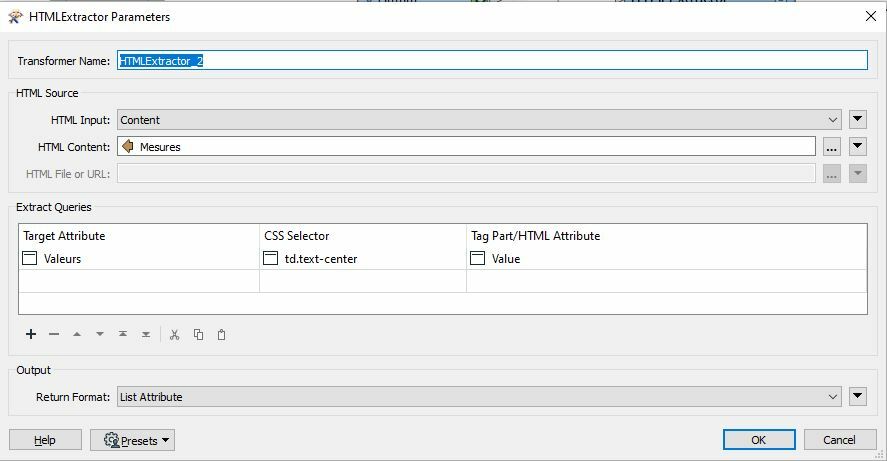



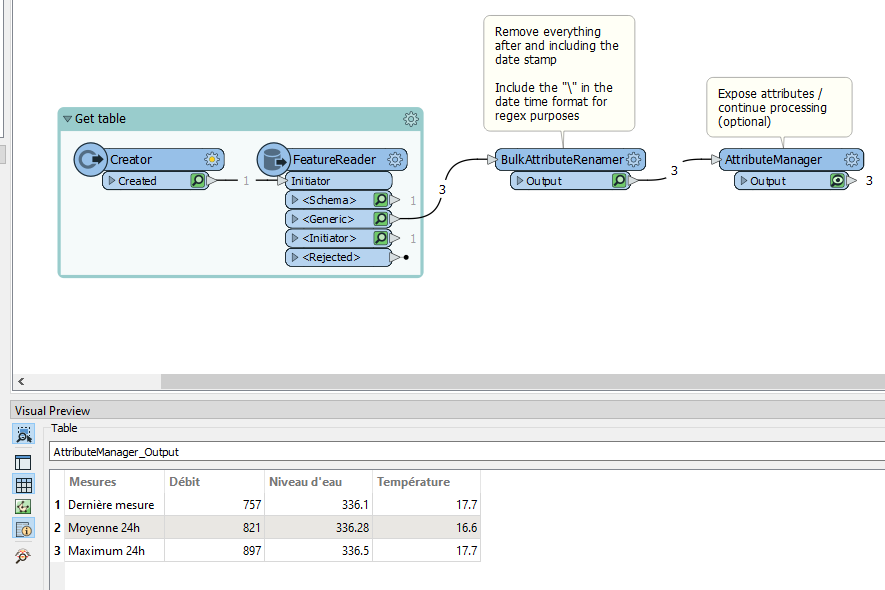 From there you can attach an AttributeManager to expose the attributes and continue processing or just attach it to your writer :)
From there you can attach an AttributeManager to expose the attributes and continue processing or just attach it to your writer :) 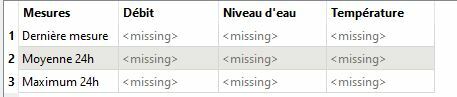 Maybe that's because the time stamp has changed but I couldnt see why as your parameters don't interfer with it.
Maybe that's because the time stamp has changed but I couldnt see why as your parameters don't interfer with it.