Hello,
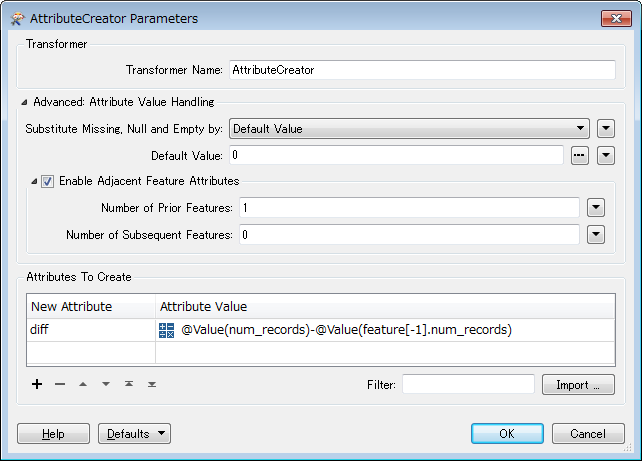
I am trying to identify any attribute changes between files in two datasets. So, every month - the dataset is refreshed (data = approx. 5,000 files) and I want to identify changes between files (with the same filename) in the updated and previous datasets.
For example, File A has 10 records in Month 1 and File A has 20 records in Month 2. I want to be able to identify how many records have been added/deleted - but the file may not necessarily have a unique identifier - so I would assume it would be based on a count?
I think that ChangeDetector is the way to go, but I am unsure? Can anyone provide some guidance on this?