


I'm trying to update (or rather replace) rows with new features and write them to geopackage. The problem is geopackage primary key is "id" that is generated when writing geopackages and I'm reading features from postgres where that same id doesn't exists and another id (let's call it ChangeID) is used as a primary key. ChangeID does exist in the geopackages and postgres table but geopackages primary key must be "id".
Unfortunately I have no control over why the id's is implemented like this. Also I know i could read those geopackages in to fme to get the "id"s but the problem is the dataset is hundreds of geopackages resulting in 100 millions of rows so the whole workflow is designed no to do that because that would result to weeks of runtime. I have a workflow to get rows that need to be replaced but fail to write them into geopackages because i can't use ChangeID to replace the rows because of different primary key.
I know there is a way to set match row id in postgres writer but can't find that option in geopackage writer. Is there way to replace those rows based on my ChangeID that is not hte primary key of geopackage or some another way around it without reading all those geopackages in?



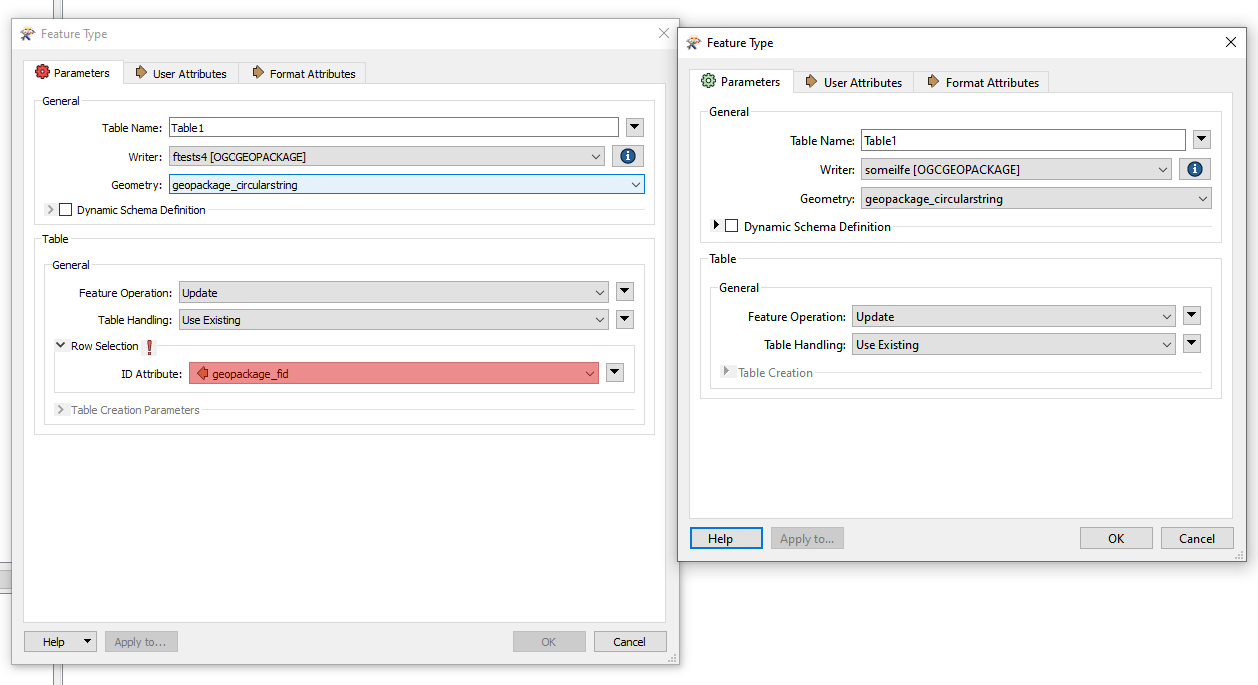 I'm not sure if there was a problem in the FME 2020 version and they removed it or if for some reason it's missing.
I'm not sure if there was a problem in the FME 2020 version and they removed it or if for some reason it's missing. 




