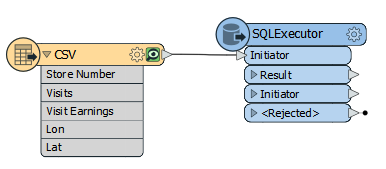
Hi everyone,
For each record in the CSV file, I want to find the closest point to it from a SpatiaLite database using SQLExecutor. What's the most efficient query that I can use to tackle this task because my SpatialLite DB contains over 35 mil points? Thanks in advance!