I need to extract the distinct attribute values of each field/column. An example is provided below:
Input
Owner Building_Type Building_ Age
Row 1: Steve Office 1970-79
Row 2: Adam Office 1980-89
Row 3: Steve House 2001-5
Output:
Owner Building_Type Building_ Age
Row 1: Steve Office 1970-79
Row 2: Adam House 1980-89
Row 3: NULL NULL 2001-5
Any help will be appreciated.
Best answer by jkr_wrk
If you need all distinct values for all attributes. First do an attributeExploder.
Be aware that FME shows attributes that are hidden after the attributeExploder like: fme_geometry,fme_type,fme_feature_type. There is no way to remove them all before the attributeExploder so you should test (filter) them out after the exploder.
Use an Aggregator (attributesOnly) with groupBy attr_name,attr_value as mentioned before. Or… Use a Samples with First 1 Features and a groupBy on attr_name,attr_value. This is a non-blocking transformer unlike the Aggregator. Or use a DuplicateRemover.
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
There are likely a number of ways to achieve this unique value
Aggregator, apecifying the column of interest as a group by
Add an AtrributeFilter and run with the feature cache turned on. This use the cache to populate the filter ports to sort features into each output port
A StatisticsCalculator with group by and using the string with a Min, should find each unique value and has the benefit of allowing you to also add count statistic to know how many times that values is in your dataset
I’m sure there are many other ways, but read up on group based processing
There are likely a number of ways to achieve this unique value
Aggregator, apecifying the column of interest as a group by
Add an AtrributeFilter and run with the feature cache turned on. This use the cache to populate the filter ports to sort features into each output port
A StatisticsCalculator with group by and using the string with a Min, should find each unique value and has the benefit of allowing you to also add count statistic to know how many times that values is in your dataset
I’m sure there are many other ways, but read up on group based processing
I have tried something similar but this does this per field whereas I want every field. I can do this for every field but I feel like that is quite a lot of transfromers.
If you need all distinct values for all attributes. First do an attributeExploder.
Be aware that FME shows attributes that are hidden after the attributeExploder like: fme_geometry,fme_type,fme_feature_type. There is no way to remove them all before the attributeExploder so you should test (filter) them out after the exploder.
Use an Aggregator (attributesOnly) with groupBy attr_name,attr_value as mentioned before. Or… Use a Samples with First 1 Features and a groupBy on attr_name,attr_value. This is a non-blocking transformer unlike the Aggregator. Or use a DuplicateRemover.
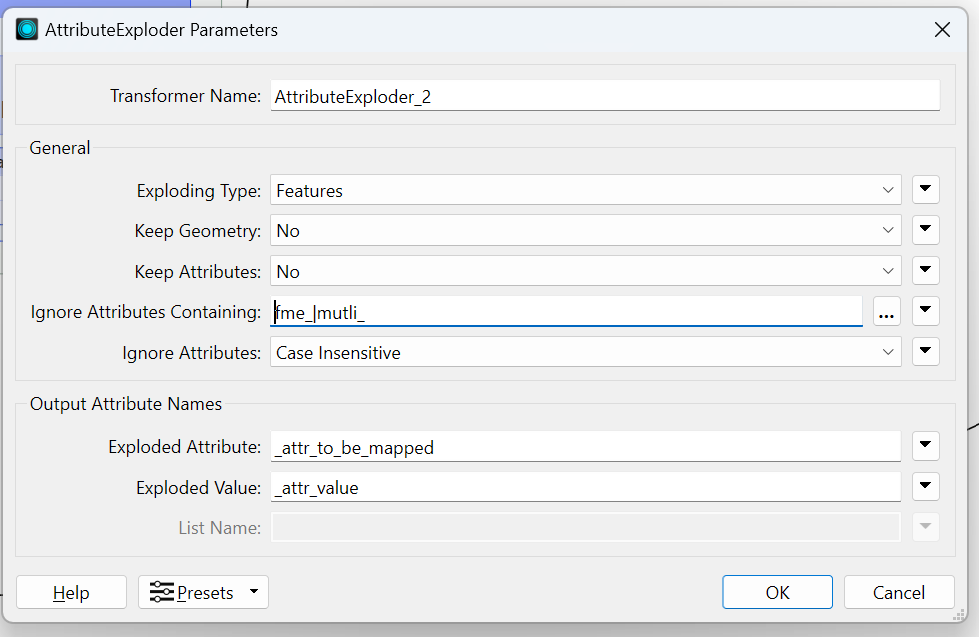
@jkr_wrk You can also exclude unexposed attributes like fme_geometry in the AttributeExploder.
This exploder ignores the usually unexposed fme_ attributes
Since the AttributeExploder can be really slow I try to minimize the number of attributes whenever I use it. The Ignore Attributes Containing can really cut that down. You can use several searching strings separated by a |.
@jkr_wrk Thank you, I just tested what adding ^does and it works for me. With the ^, the ignore function only selects attributes whose names begin with the searched values. That will make my workspaces a little more reliable.
How did you know to try and do that? Does that mean the ignore logic uses regex?
BTW I don't know when this functionality was introduced but it was available in the 2023 editions I used as well.
Enter a regular expression, and matching attributes will be ignored.
For example, if the source data is CSV, you could use the regular expression ^fme_|^multi_|^csv_ to ignore any attributes starting with fme_, multi_, or csv_.

")





")