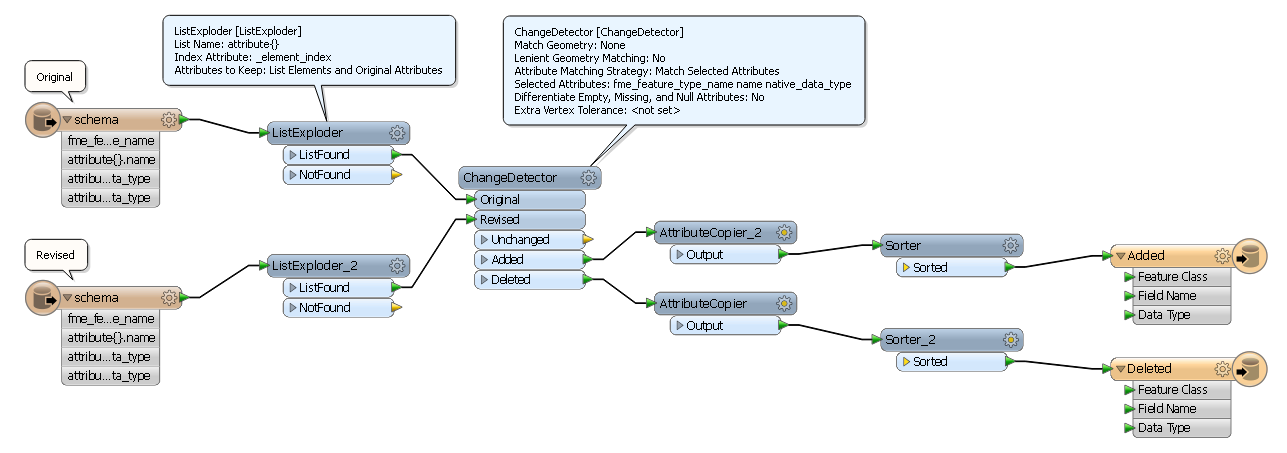
I have two lists (each an excel file) and I want to compare each item in the list of one file to each item in the list of the other excel file.
The lists could be alphabetic or numeric or a combination of both (normally arranged in a column). Example: list#1 = john, ralph, street, egg, computer, mouse. List#2 = Mike, Nike, keyboard, 123, run, letters, words, eye, fingers, help, egg
My desired result should be "unique items" = john, ralph, street, computer, mouse, Mike, Nike, keyboard, 123, run, letters, words, eye, fingers, help. And "Matched items" = egg
Help is greatly appreciated it. As detailed as possible please since I am just starting using FME. In fact posting the workspace for me to examine and learn from would be ideal. Thanks