

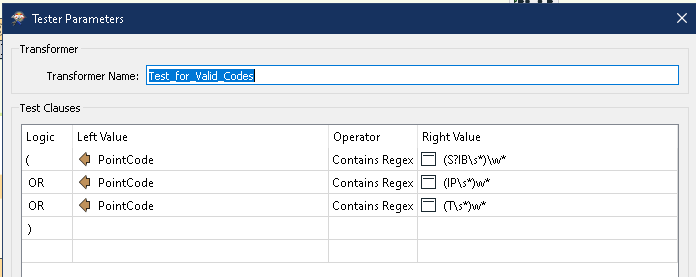
I am processing a large amount of simple data: Points with attributes. I want to filter the data by a specific set of attributes, some of which have wild cards. e.g., "T", "T BASE", "T BENT" should all pass through. For each run, a user will be specifying the valid attributes by putting them into a file (probably text), which will be read in at the start of the process. I mention using a list, but they could go into a table as well if that would work better.

Question
How do I test/filter attributes using a list with wildcards?


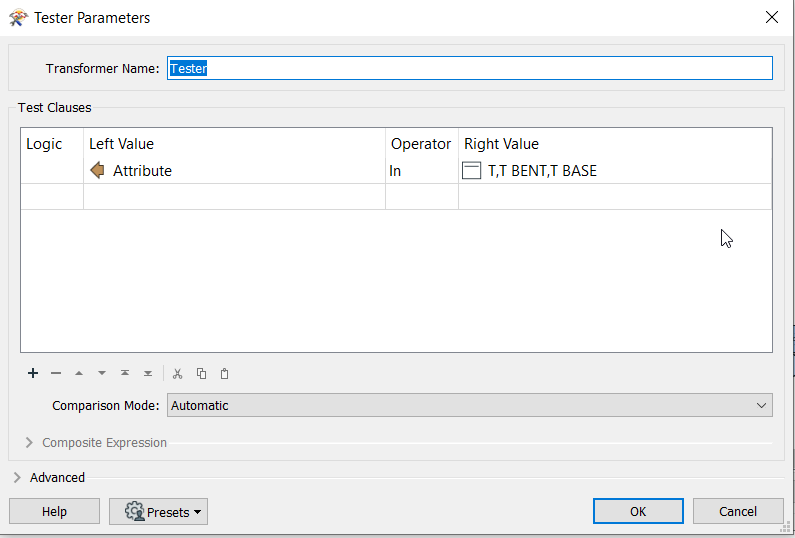
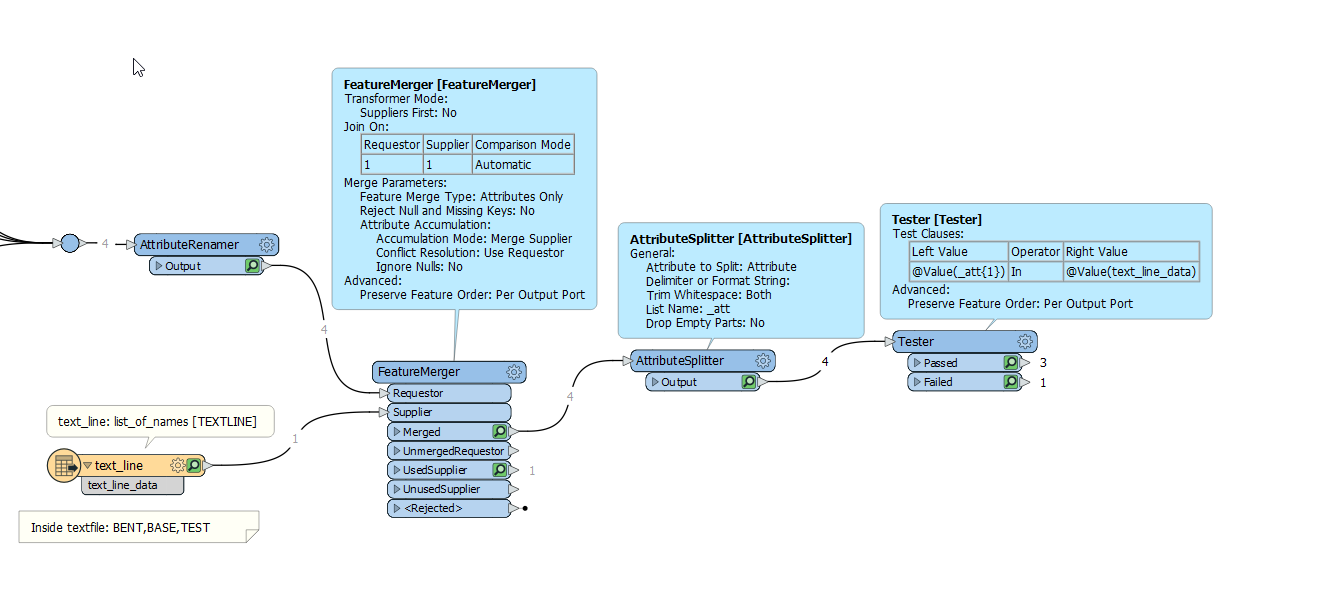

")






Login to the community
No account yet? Create an account
An FME Account is required to contribute
LoginEnter your E-mail address. We'll send you an e-mail with instructions to reset your password.