


Hi, I need some help setting a basic test with the tester transformer. I'm trying to fail rows from a feature if they match any values in a csv file I've added as a reader. I'm having some issues getting things configured correctly.
So something like NOT @Value(field) Contains <Right value>. But I can't seem to connect the right value. Connecting the csv as an input isn't what I want, but I cant figure out the syntax to use in conjunction with '$(SourceDataset_CSV2)'.
Sorry for this basic question but I couldn't figure this out looking at the documentation. Thank you.
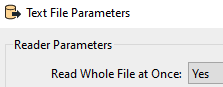
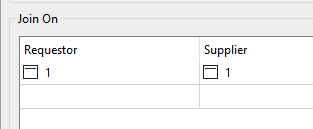 Coming out of the merged port, you should now have the same number of features coming in your requestor port with an additional attribute containing the entire csv.
Coming out of the merged port, you should now have the same number of features coming in your requestor port with an additional attribute containing the entire csv.

