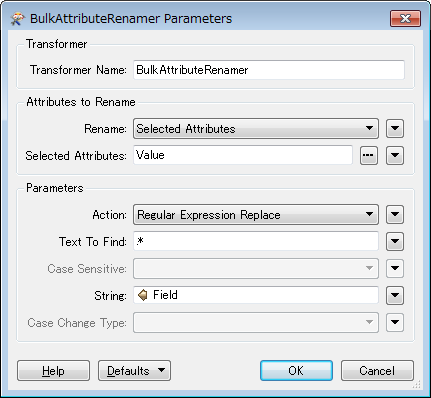
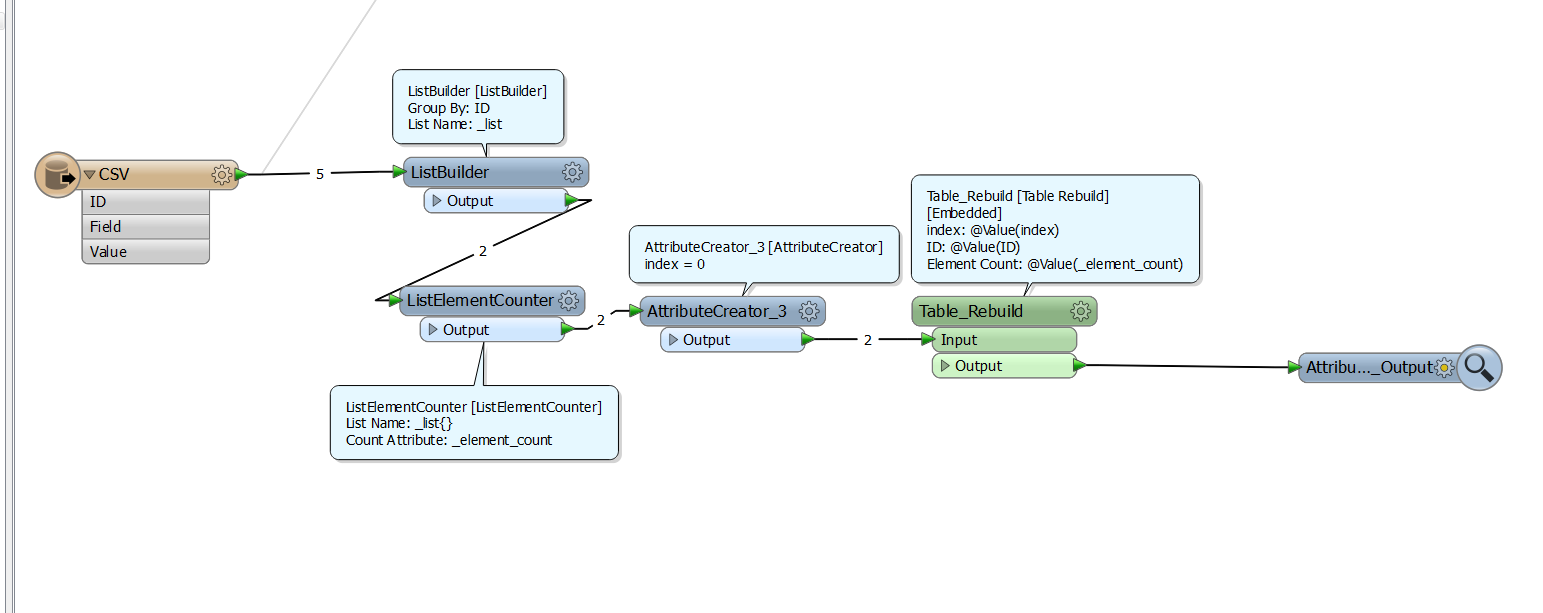
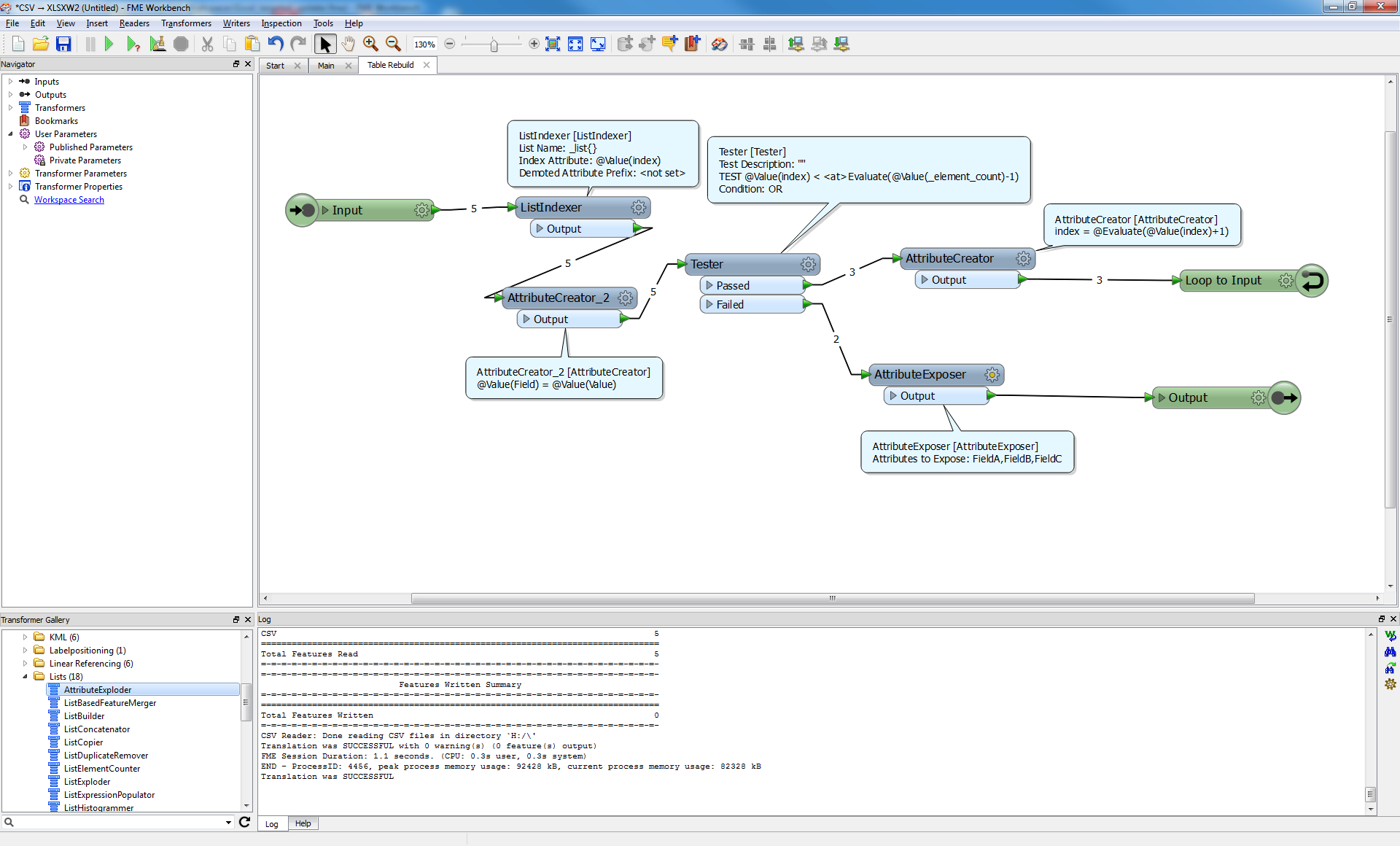
I'm having trouble restructing my (aspatial) data from what I can best describ as multiple rows per uninqe identifer each containing a feild name and respective value to a single row per feature per feature where there field name values become columns. The example below probably explains this better:
---INPUT----
ID,Field,Value
1,FieldA,Cow
1,FieldC,Sheep
2,FieldA,Dog
2,FieldB,Mouse
2,FieldC,Cow
---DESIRED OUTPUT---
ID,FieldA,FieldB,FieldC
1,Cow,,Sheep
2,Dog,Mouse,Cow
Does anyone have any tips as to how this is best don? Aggreagting is based on the ID is easy, but manipulating the resultant list items into the format of the desired output is eluding me.
Regards. Rob.