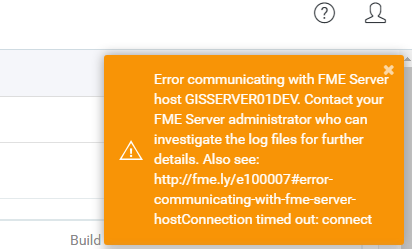
Hi everyone,
I have a parent workspace that looks like a series of FMEJobSubmitter transformers:
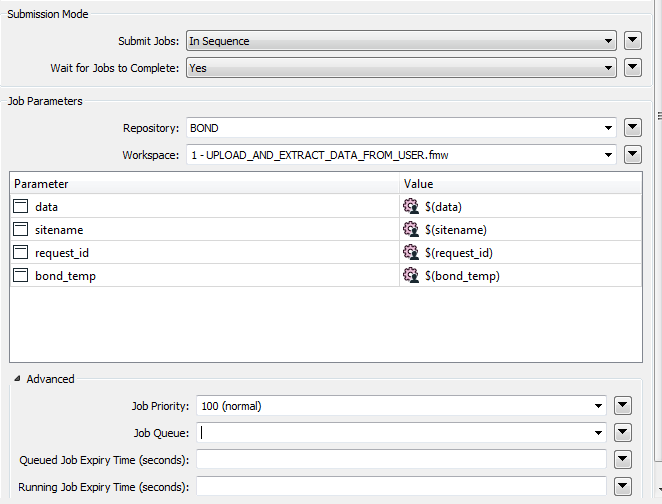
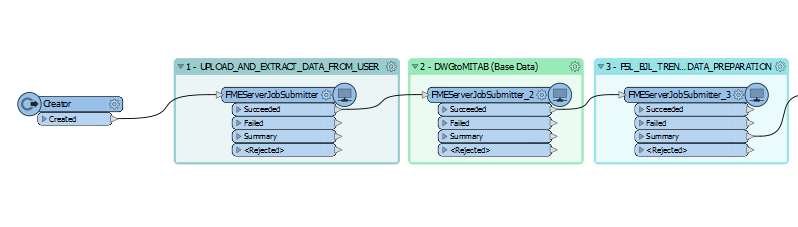 Each FMEServerJobSubmitter set up at below:
Each FMEServerJobSubmitter set up at below:
Submit Jobs: In Sequence
Wait for the Jobs to Complete: Yes
When I call this parent workspace from the Web Interface, something weird is happening. First job gets submitted straight away and it becomes Completed after a second. Then the second one will only appear in Running jobs after about 45 seconds. It is not in the Queued and one of the engines is not doing anything.
The same case is happening for the rest of the workspaces - they will only appear in Running after about 45 seconds once the previous one gets Completed.
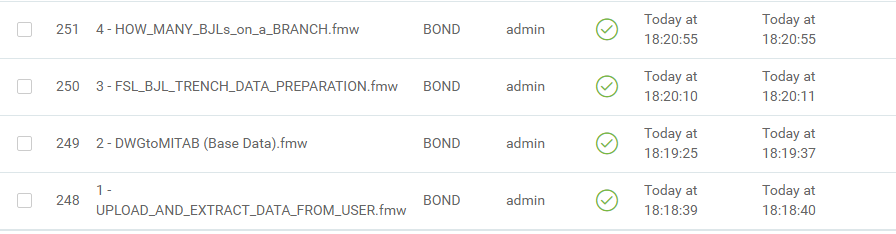
It is worth mentioning that we installed our FME server as distributed components (3-tier).
If it is installed as Express, it is working fine.
Any help, please?
PS We are using the latest build (20596)


 e attached.
e attached.  The job 312 finished at 22:25:45, and the 313 started at 22:26:29, which is 44 seconds after the 312 has finished.
The job 312 finished at 22:25:45, and the 313 started at 22:26:29, which is 44 seconds after the 312 has finished.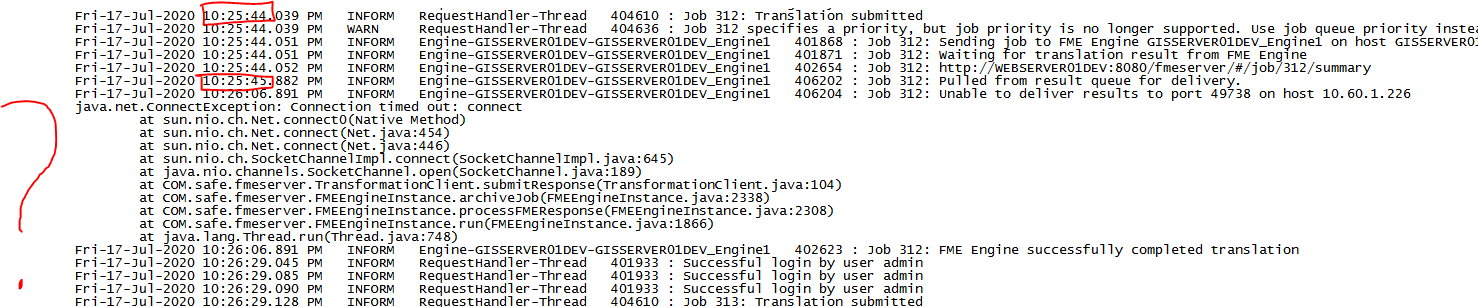 So, 312 job was submitted at 10:25:44, at 10:25:45 it was finished ant than there was a problem delivering results and some other stuff before job 313 was submitted. Not sure where the problem is.
So, 312 job was submitted at 10:25:44, at 10:25:45 it was finished ant than there was a problem delivering results and some other stuff before job 313 was submitted. Not sure where the problem is.