



Hi All,
I have created a workflow that reads a few large GIS datasets in vector format across different areas. To avoid reading all the records in the dataset and reduce time I have used the FeatureReader transformer which is connected to the layers and an Area of Interest. The Spatial Filter option is ‘turned on’ as Boundary Boxes OGC-Intersect to read only those records within the Area of Interest. The problem is still takes ages to read,
I have got a few FeatureReaders within the workflow and I was thinking to use only one FeatureReader (as all the data comes form the same GDB) to improve the performance,
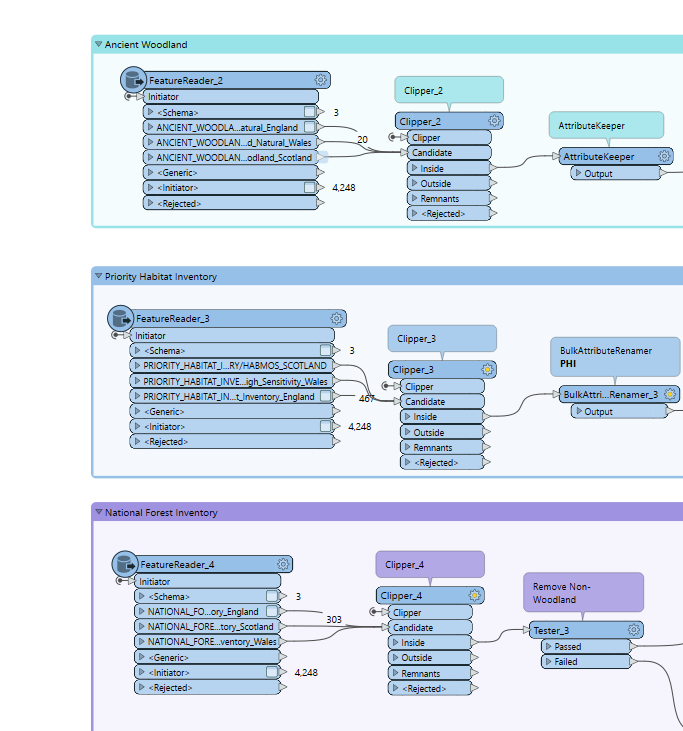
Any ideas to improve the performance of the workflow?








