Hi,
I'm trying to create a workspace that reads any feature class of a certain geometry type (e.g. line or point) from an Oracle Spatial database and writes it into an SDE Geodatabase. Since around 200 feature classes need to be processed, a manual transformation is not possible (meaning that a reader and writer are created for each feature type individually). I have tried different approaches that did not work:
- Generic reader: Expects as an input a "source dataset". What I have is an database, however (I need to provide its connection parameters via published parameters instead of providing a dataset)
- Dynamic reader (merged feature types): An Oracle Spatial reader together with "merge feature types" and a filter on "Features to Read" -> "Feature Types to Read" (provided by a published parameter) did not work, because its schema does not change with the feature classes dynamically.
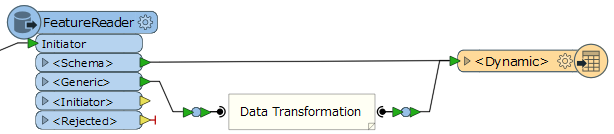
I finally used a FeatureReader in combination with a dynamic writer, which would work perfectly, if no attribute transformation is required (or for the initial writing process). However, I want to write only incremental updates in the SDE geodatabase and thus need the check the attribute values regarding changes. But because the FeatureReader outputs the data and its schema separately, this seems not to be feasable (easily).
Is there a possibility to merge the data and its schema, so that subsequent transformers can work with the attributes? A method without PythonCaller would be prefered, but I am grateful for hints regarding PythonCaller as well. Or are there other approaches than using FeatureReader which would fulfill my conditions?
Thanks in advance!
Best regards,
André