


Hi,
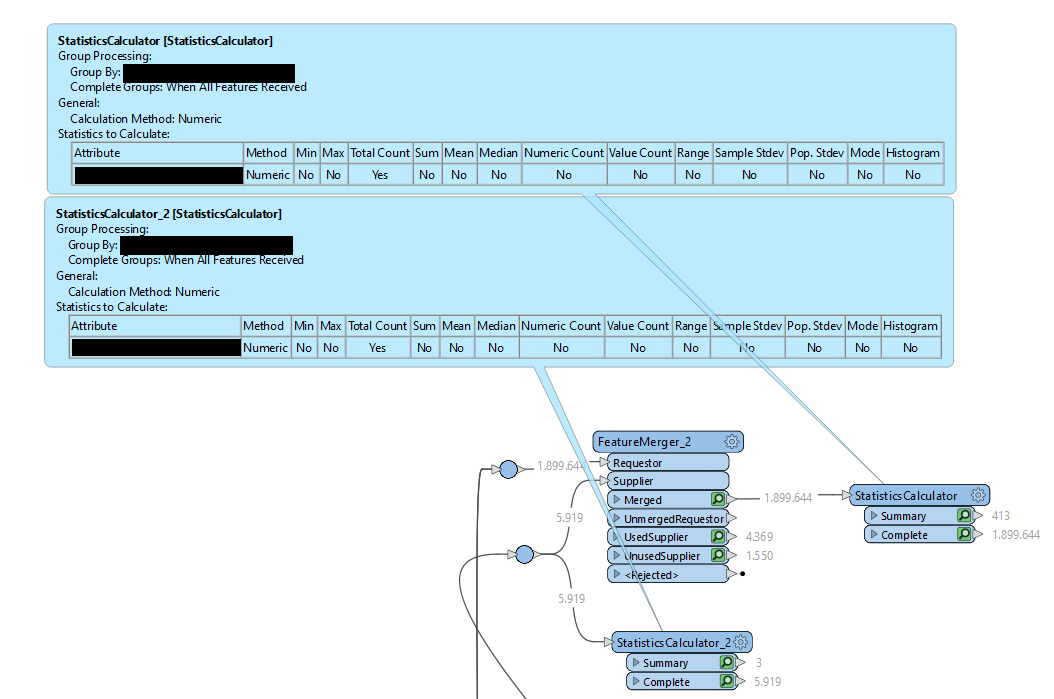
Unfortunately i cannot provide the test data due to confidential data. I also cannot encode/dummify the data because then the issue no longer occurs. It is likely related to the large amount of data being processed. What I can include is the image you see here.
My question is: how can the following happen? Is this a bug?
I merge two flows, both have a lot of attributes. Requestor is 1.9m features. Supplier is 6k features. Supplier has only in ~1% of cases a value for attributes ‘X’ and ‘Y’ - the other 99% is <missing>. But supplier also has a lot of other data and attributes.
After merging, for attributes x and y a lot more values are found. They are chinese or japanese characters. They are supposed to be numbers or english words.. Also I think they are getting also values from other attributes entirely, but then the actual value instead of random chinese or japanese characters. How is this happening?
I am sure that: the attribute I test is the same (I duplicated the statisticscalculator). I am sure that: the attribute doesnt exist in the requestor flow.
My FME version is 2023.0.0.3; build 23319.



")



