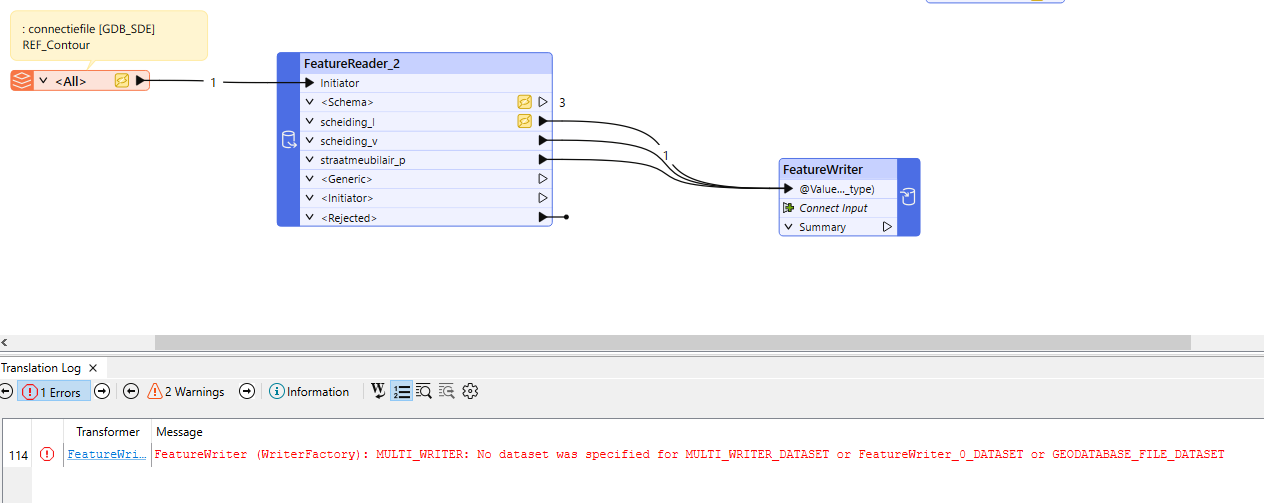
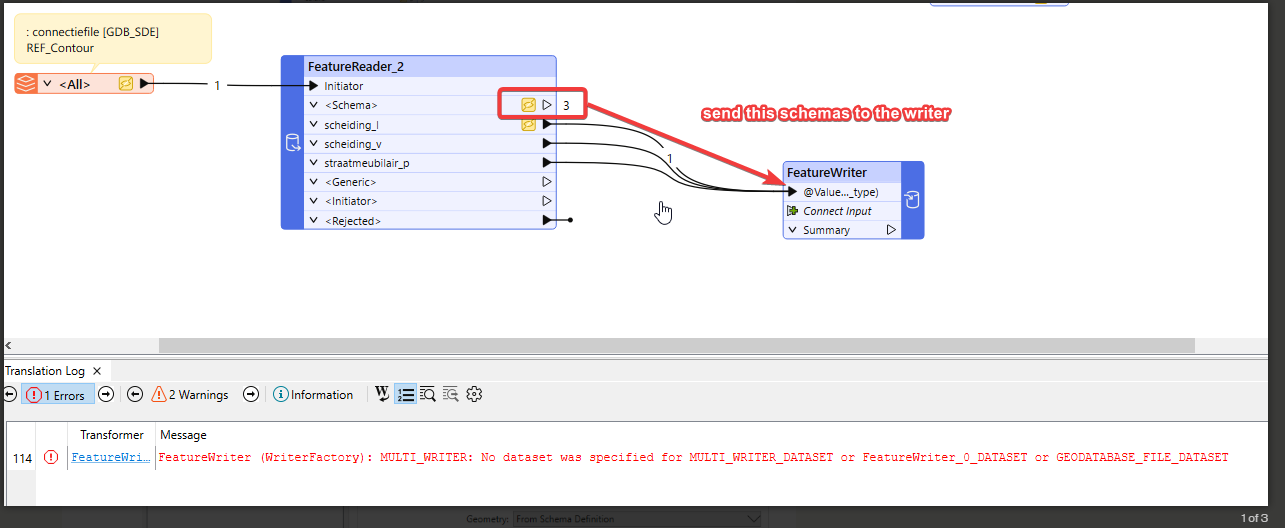
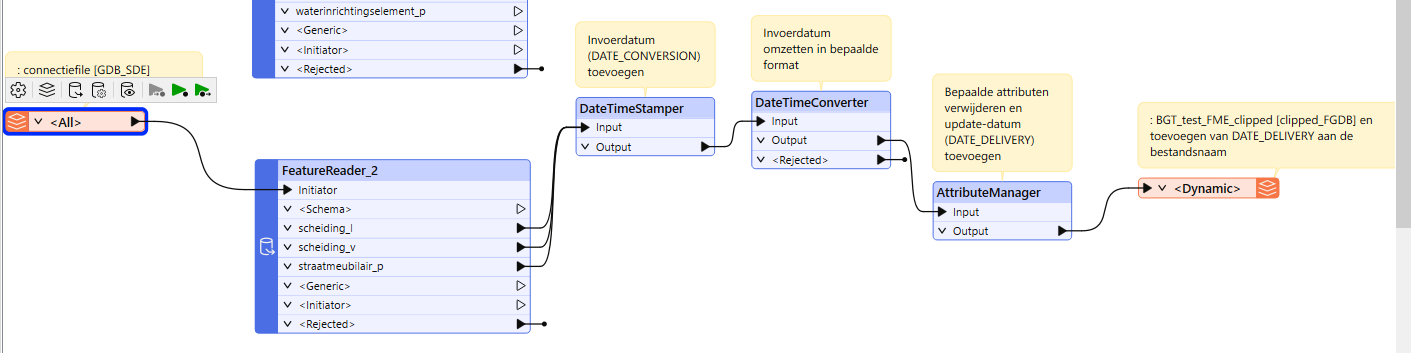
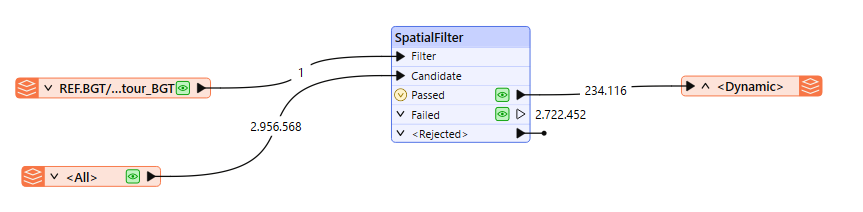
Hi, I use a FeatureReader for two purposes: to clip features with a polygon, and to select some desired geodatabase layers (of several geometry types: point, line and polygon).
After the “succesful translation” the new geodatabase has been created. However, this database seems to be empty.
What could be possible causes? Wrong Schema/Data Features of the FeatureReader? In the Reader I have:
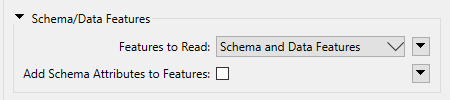
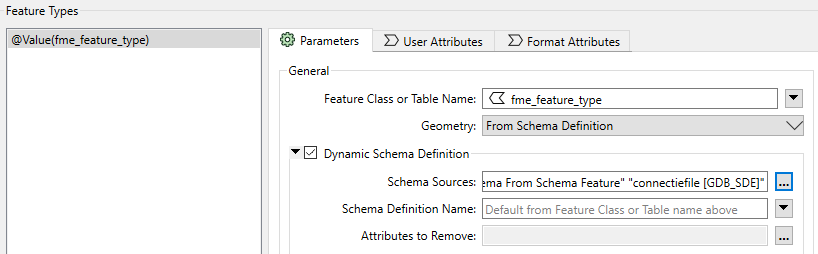
In the Writer I have:

Connectiefile is the file where the polygon for the clipping purpose can be found. Other schema sources are not available.
Any ideas?