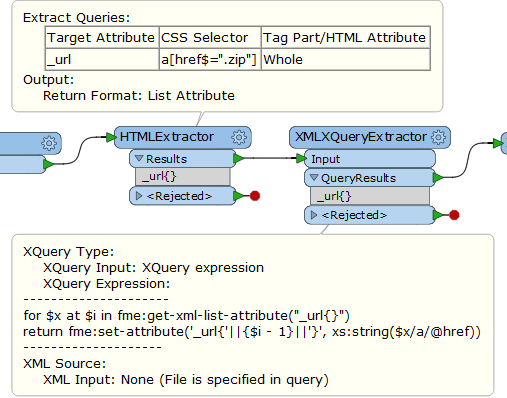
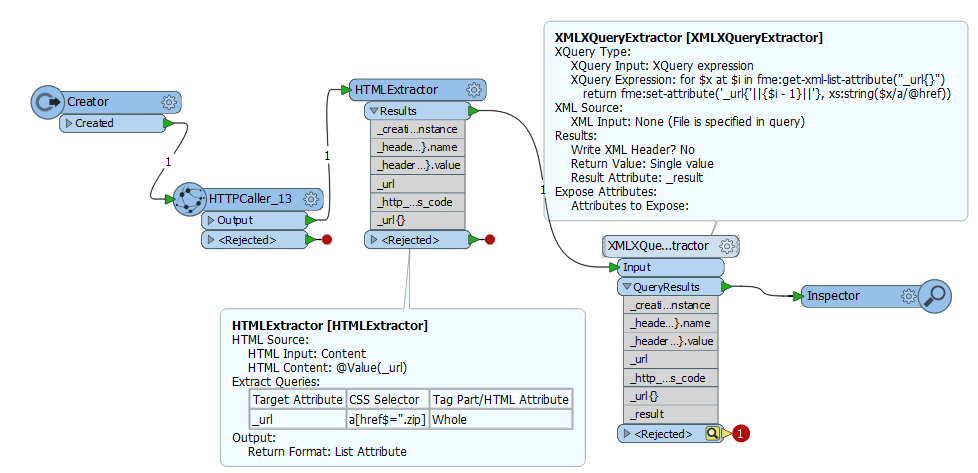
I'm trying to extract a download-URL within a href. I have tried using the HTMLExtractor, ListExploder and XMLYQueryExtractor to isolate the specific URL to an attribute but with no luck.
I need too isolate the URL with the .zip (http://gpt.vic-metria.nu/data/land/NM.zip) from this http://mdp01.vic-metria.nu/geonetwork/srv/en/csw?request=GetRecordById!!!service=CSW!!!version=2.0.2!!!elementSetName=full!!!id=c6b02e88-8084-4b3f-8a7d-33e5d45349c4!!!outputSchema=csw:IsoRecord" target="_blank">webpage . Is it possible and how?