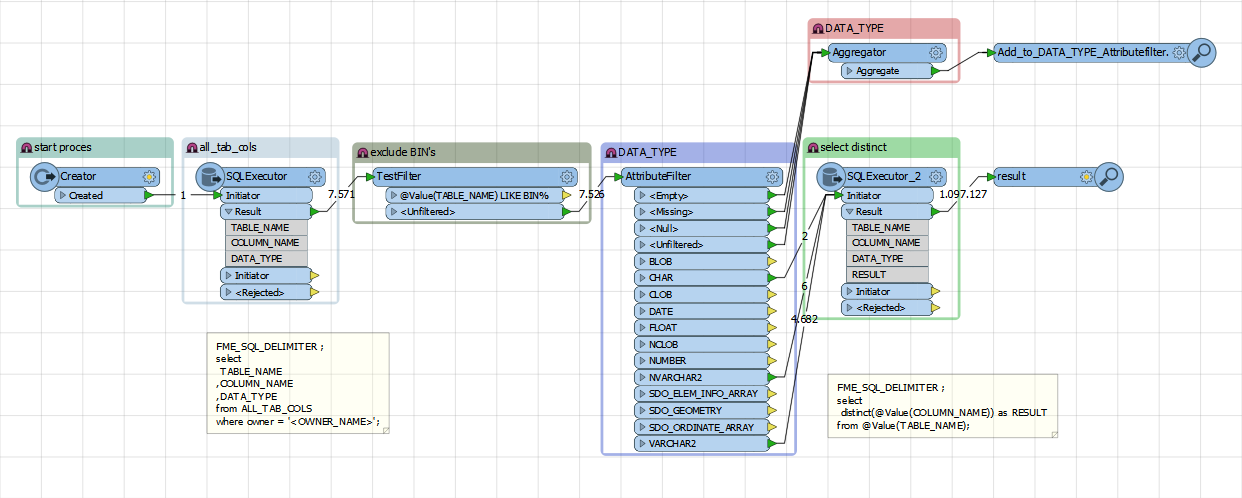
I'm trying to determine all of the unique values for each field for a dataset. I'd like to create a dynamic workspace because I need to do this for 100+ datasets. Each dataset has a different number of fields with different field names.
I'd either like to export a csv for each dataset with the field name and all the unique values listed.
The data will be coming from feature classes in an Oracle database. Any suggestions?