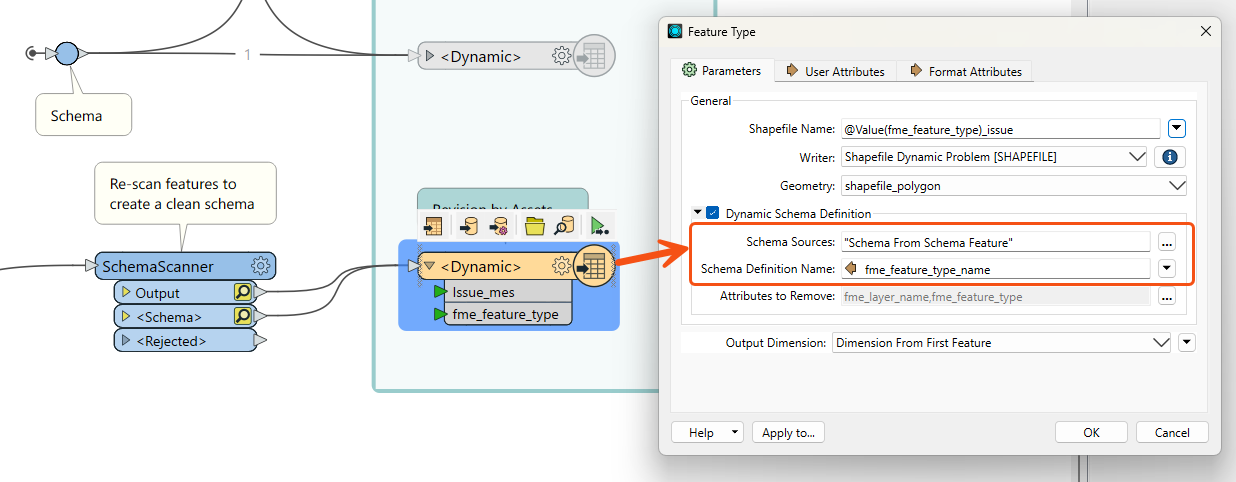
The workbench I am putting together contains a feature reader to a dynamic write in several locations.
The workbench itself detects shape files in a folder location, validates projection, geometry and AssetID attributes.
Then writes out any identified errors to a shape file for upload in another step.
The dynamic write of the "errors" shape file works however the dynamic write of the upload file encounters a warning where the below appears in the log:
Cannot define schema for '@Value(ENCODED,fme_feature_type)' as the feature does not contain schema information.
While we have the schema mismatch the remainder arrive correctly.
The features arrive with the new layer name that I want to use.
Testing my workbench I have found that the dynamic writer performs as expected (and outputs the shape file) for every stage up to exposing the fme_feature_type, mapping the new layer name and setting the dynamic reader to the new layer name.
I have tested this in the latest version (2023.1.1.1) and received a similar result.
Has anyone experienced this encoded value mismatch on the schema before and what is the best way around it?
Thank you.
Michael.