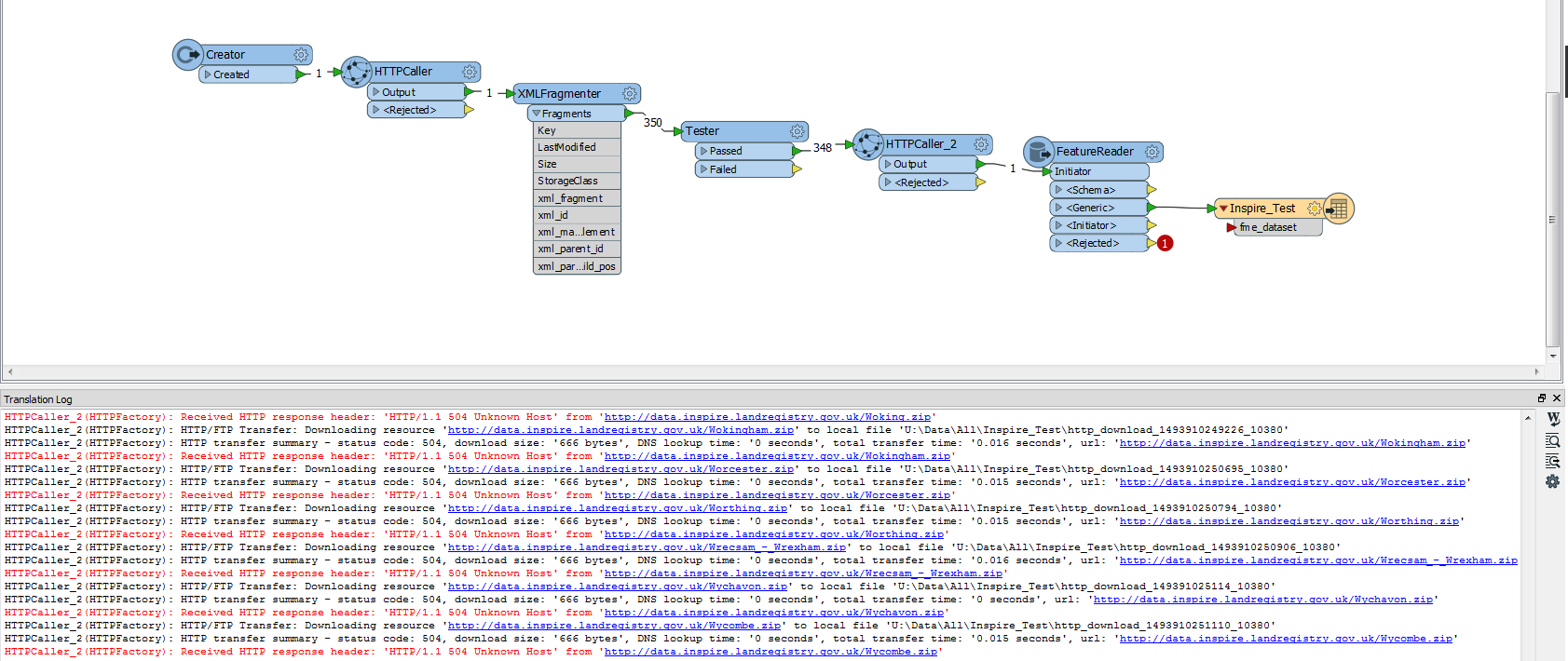
Hi all,
I've got a problem that I'm trying to solve. I need to download a large number (circa 50) zip files from this website. They all follows the same format, it's
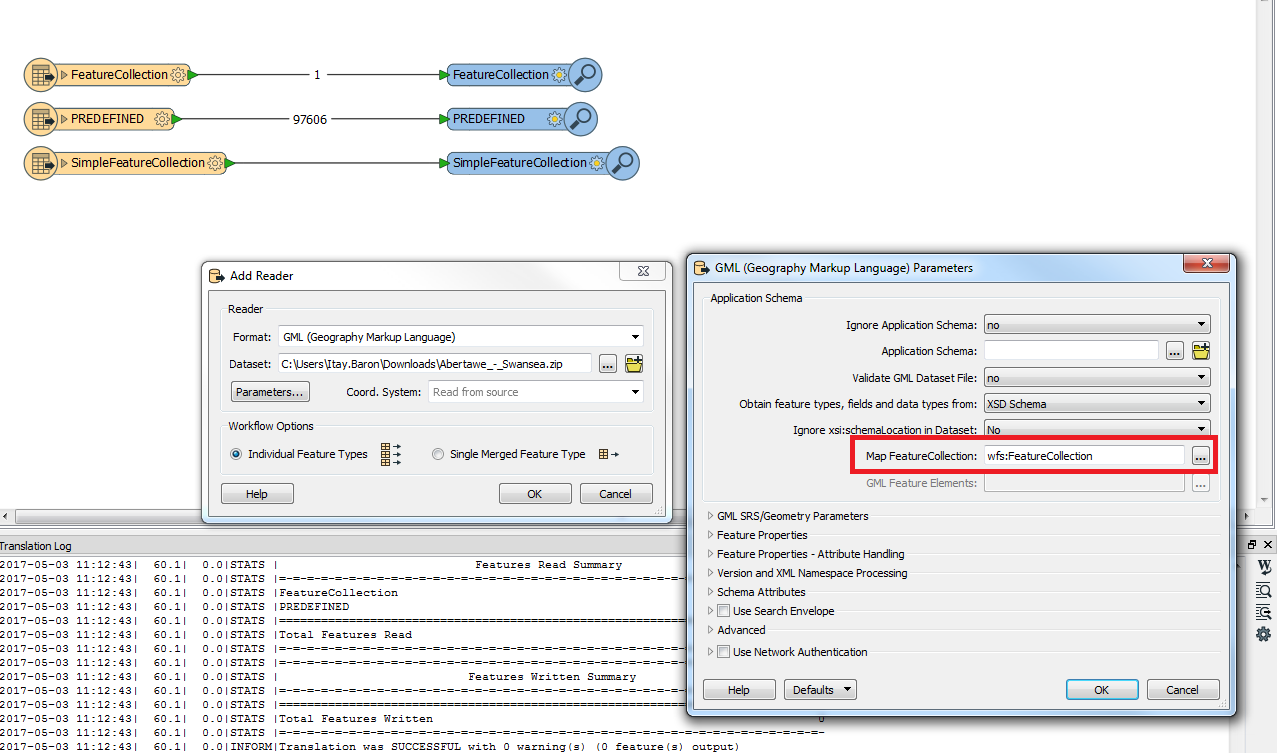
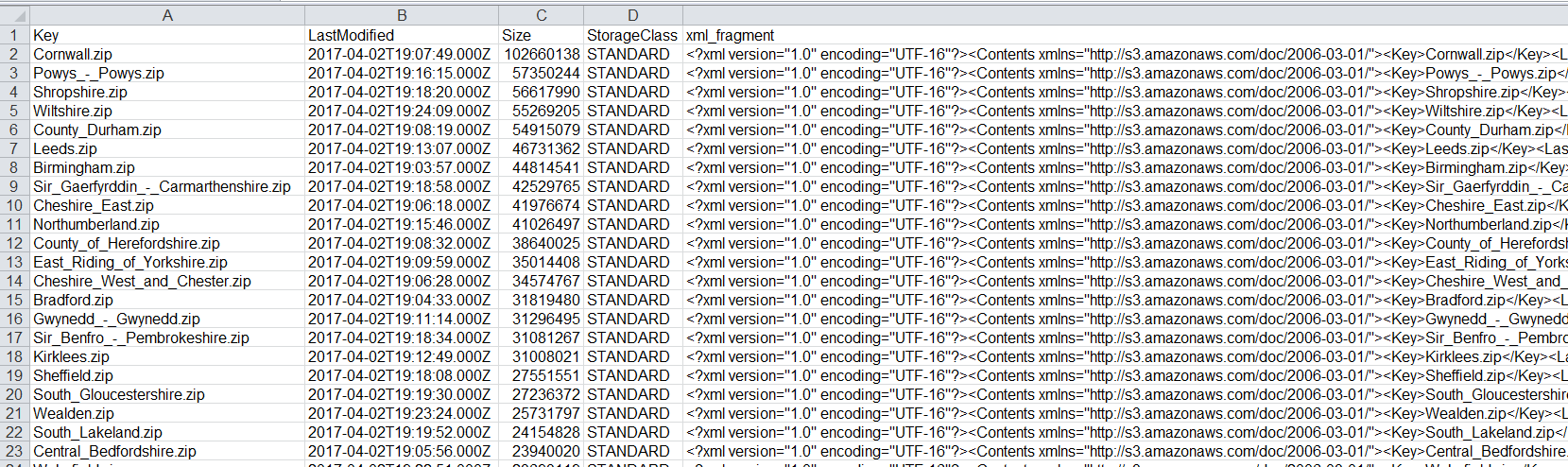
http://data.inspire.landregistry.gov.uk/Abertawe_-_Swansea.zip. In each zip file is a GML for that local authority area. I need to download each of them and merge them as one feature in a file geodatabase. I have already tried going through manually and saving the URLs to a CSV and then using the below workbench.
1. CSV Reader.
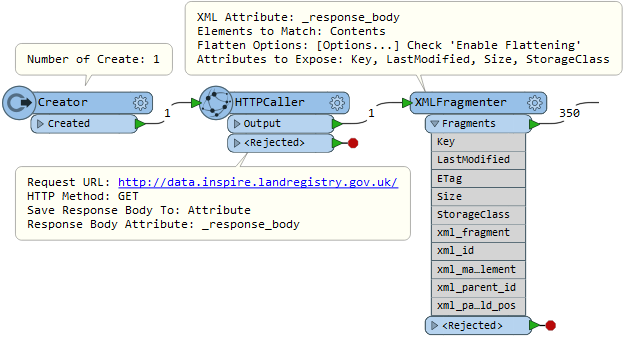
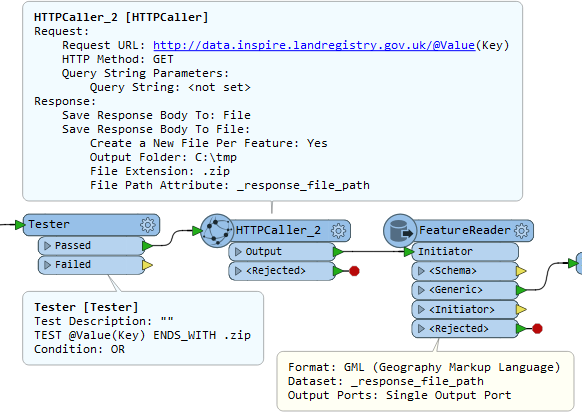
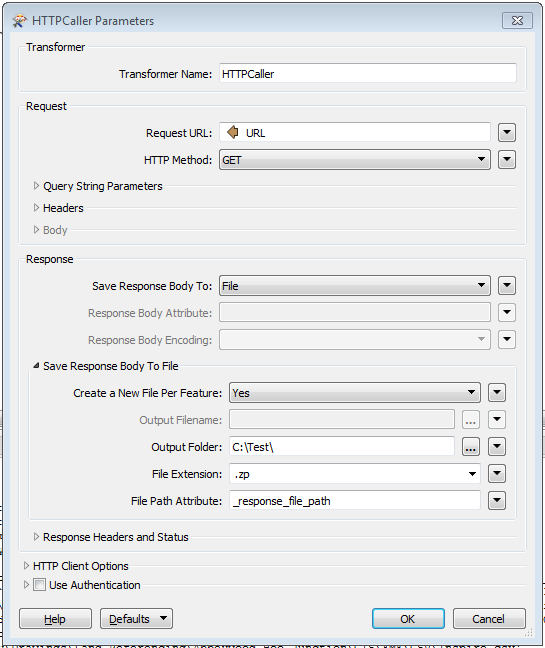
2. HTTP Caller with the following settings:
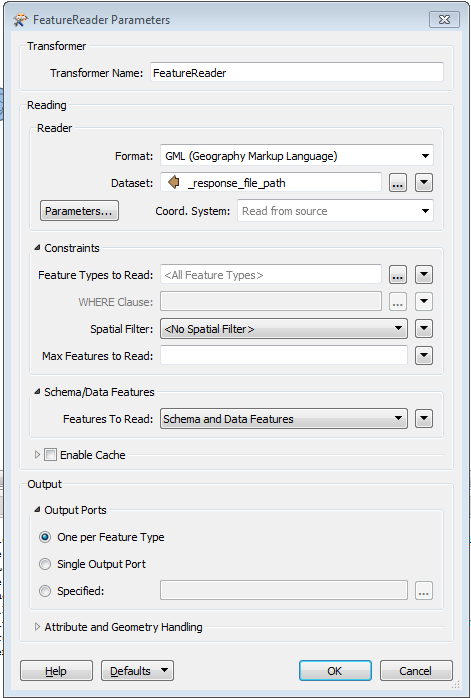
3. Feature Reader with the following settings:
3. Attribute Creator using the 'fme_dataset' as the new attribute called 'Local Authority'. This obviously creates a large file path in the following format:
I:\\UK\\OutsideLondon\\Land_Ownership\\Out_East_1\\Data\\Inspire\\Gravesham.zip\\Land_Registry_Cadastral_Parcels.gml.
I would then like to use a StringSearcher to strip out everything except 'Gravesham' so that I only have the local authority name as an attribute.
I then use a ESRIReprojector to set the projection and finally a file geodatabase writer with the geometry as a polygon and the user attributes set to automatic.
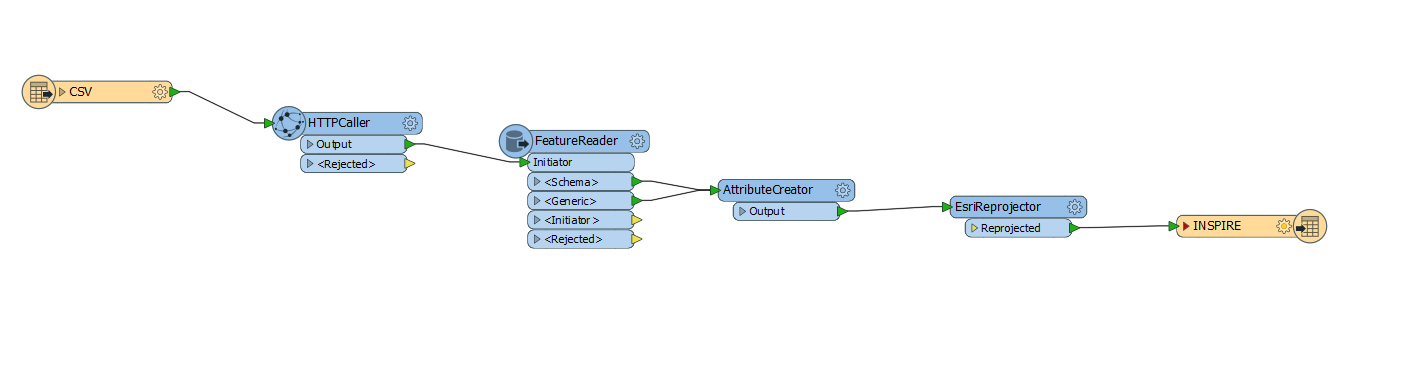
This is the whole workbench (minus the StringSeacher because I haven't worked on the regex yet.
When I try and run this I get the following error:
XML Parser error: 'Error in input dataset: file:///xxx/yyyy/zzzz/GIS/Data/Inspire/http_download_1493802040496_7056.html' line:1 column:103 message:unable to connect socket for URL
Along with the error, the files get read as far as the FeatureReader but all end up at the rejected port and when I inspect them there's no geometry present.
The questions I have are:
1. Is there something obvious that I'm doing wrong?
2. Is there any way to get a list of all the URLs together to be able to download?
3. Is there any source of help I can get for the regex on my point 3 above?
Thanks for any help anybody can give me.