I’m working through a data cleaning process in a workspace. I have multiple files that are different from each other in schema and attributes, but are essentially all saying similar things. Hence the cleaning.
I’m working in one workspace to make re-use of transformers a little easier, but when I’m using the FirenameParkExtractor transformer I need to identify a user parameter source for it to gather up a name to chop up. This is what that dropdown looks like:
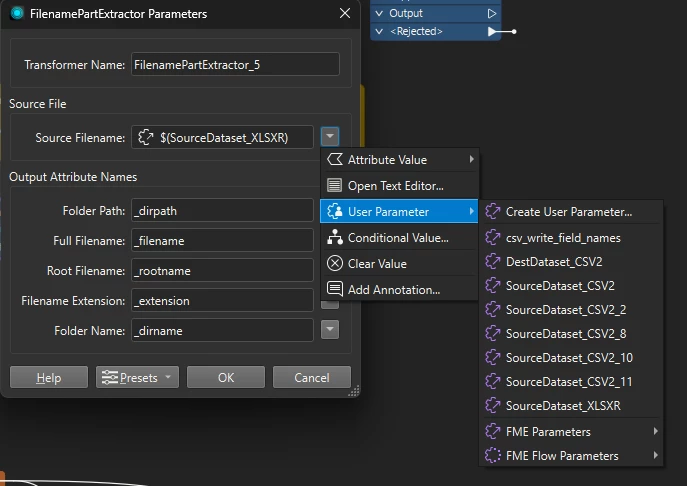
The names here do not align with how I’ve named the readers and associated files so I’m a little confused about how to make this situation easier to work with. I’d like to be able to rename the source datasets, but I’m not sure where I’d do that. Can you tell me?
As an aside, is it a bad idea to process many things in one workspace? Should each file get it’s own? Is there some helpful documentation out there about designing workflows? (I’ll be searching on that just now, but I thought of the question as I was writing the post!) Happy to field tips from more experienced FME handlers.
Thanks!