Good evening,
I have two shapefiles, which I want to merge with each other and then continue working with the partial results. One shapefile contains the boundaries of the municipalities and the other shapefile contains the BoundaryBoxes of the LAS tiles. Since the amount of data is too large, I want to process the data community by community.
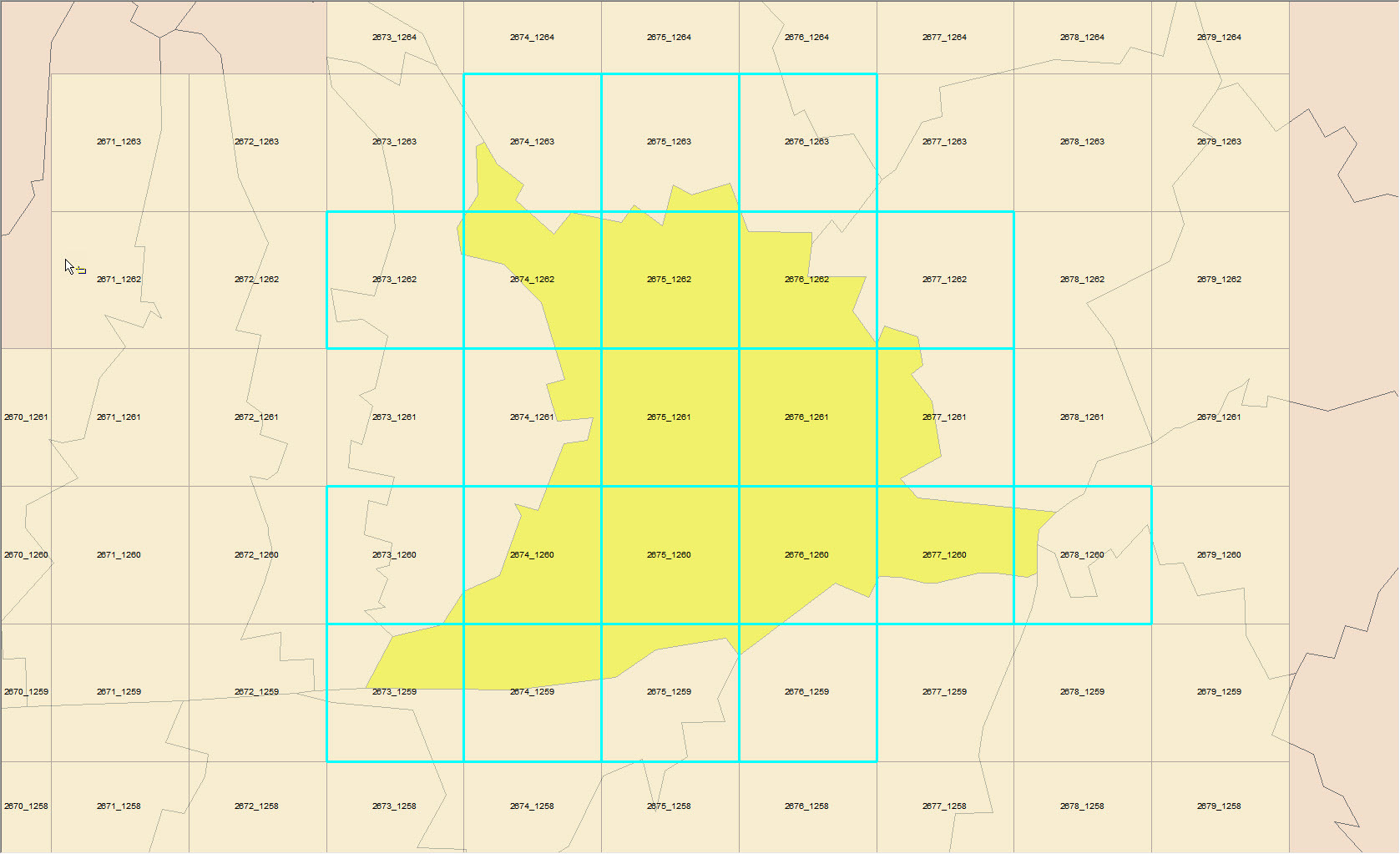
The tiles marked in blue contain the names and paths of the individual LAS tiles in an attribute [ID].
In my Workbench I perform a spatial selection using the SpatialRelator. For this I connected the shapefile with the information of the LAS tiles to the supplier port and connected the community boundaries to the requester port. 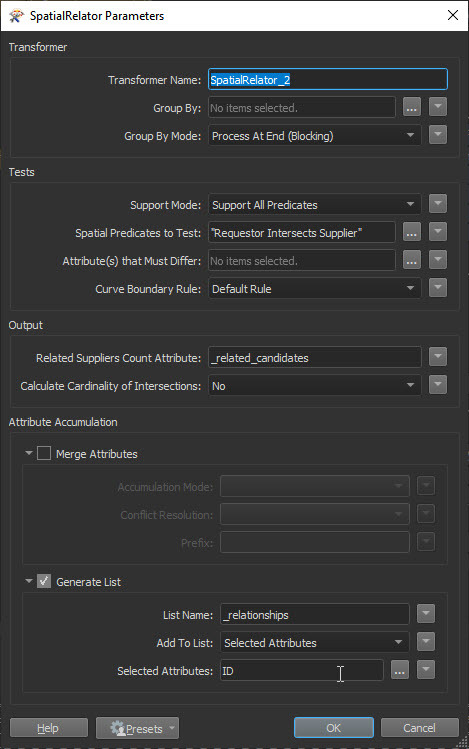 .
.
As a result, I get a list of all elements that contain the community (like the tiles marked blue in the first picture). To check if the selection is correct, I exploded the list with the Listexploder. The result is correct and so far everything is clear.
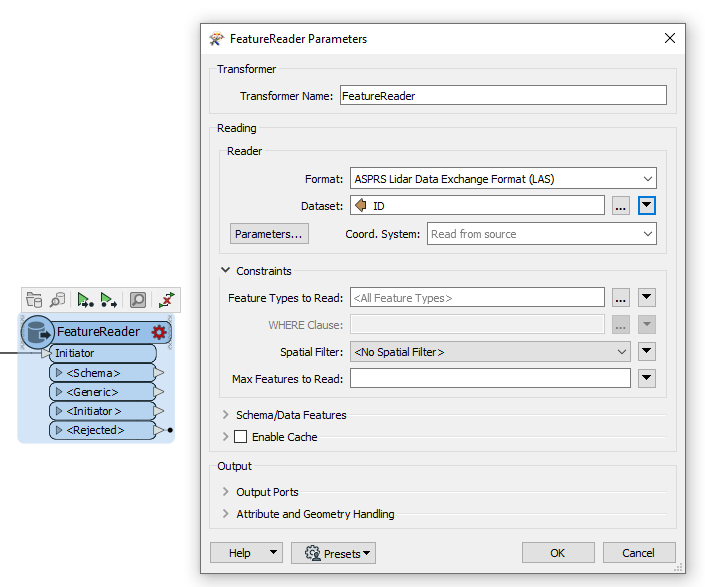
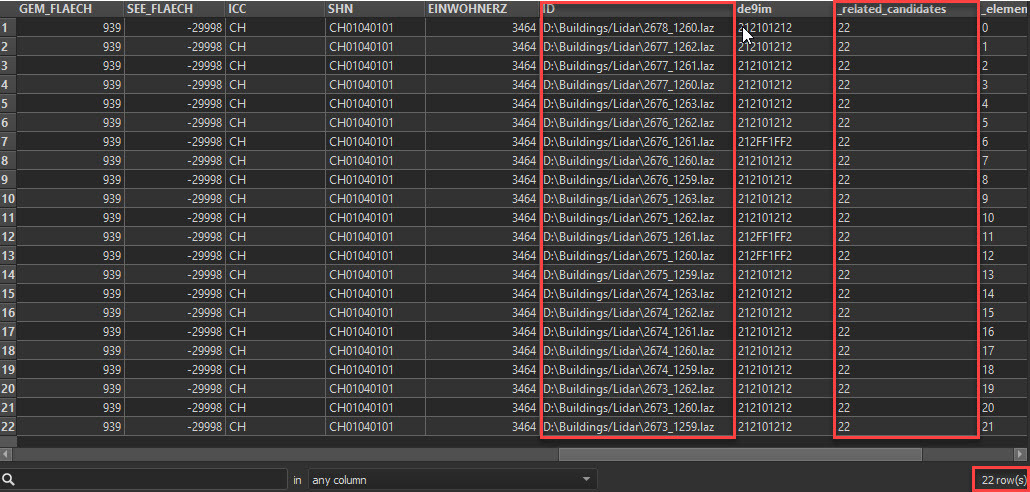 Next, I want to read the 22 selected tiles, which are stored in the [ID] column with the path, from the directory of all tiles and process them for this municipality. I would do this with the FeatureReader, but I am not sure how to set up the settings so that only these 22 tiles are read in and are available for further processing. All my attempts with various settings either didn't bring any data for further processing or all data in the (total) data directory were read in. My question now is, how do I configure FeatureReader to read only the elements of my "_relationships" list, their path and name in the [ID] attribute? Maybe there is a more efficient way?
Next, I want to read the 22 selected tiles, which are stored in the [ID] column with the path, from the directory of all tiles and process them for this municipality. I would do this with the FeatureReader, but I am not sure how to set up the settings so that only these 22 tiles are read in and are available for further processing. All my attempts with various settings either didn't bring any data for further processing or all data in the (total) data directory were read in. My question now is, how do I configure FeatureReader to read only the elements of my "_relationships" list, their path and name in the [ID] attribute? Maybe there is a more efficient way?
Thanks a lot in advance from a FME newbie.
PS: Once I have solved this problem, I wonder how I can do this automatically on a community basis (community by community). At the moment I have defined the one community directly with a tester.