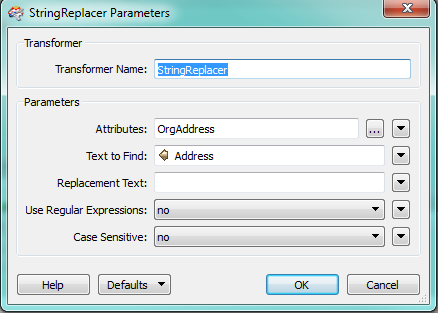
Hi , I hope this is a simple query.
I have a dataset which has a field that contains the organisation name and address seperated by spaces (see example)
I also have a gazetteer that should match the address in the first dataset without organisation name.
I want to be able to compare the two strings and extract the organisation name into a new field.
Example:
Dataset 1: Kam's Made Up Org 15 Test Street Testingham TE23 2TE
Dataset 2: 15 Test Street Testingham TE23 2TE
Desirable new field: Kam's Made Up Org
p.s. Both datasets have a unique identifier also to match them together.
Regards,