Unfortunately, changing the Spatial Text parameter didn't help in my case and I haven't gotten around to trying to figure out the Python. Thanks tho for the suggestion. I'll give it try again later on.
Cheers
As a starting point, here's sample code for the PythonCaller that will output a feature for each individual text block that is found within a PDF, as specified in the attribute "pdf_filename":
import fmeobjects
from pdfminer.high_level import extract_pages
from pdfminer.layout import LTTextBoxHorizontal, LAParams
class ExtractPdfTextBlocks(object):
def __init__(self):
# LAParams documentation can be found here:
# https://pdfminersix.readthedocs.io/en/latest/reference/composable.html
self.params = LAParams(line_margin=0,
detect_vertical=False,
boxes_flow=None,
all_texts=False)
def input(self, feature):
pdf_filename = feature.getAttribute('pdf_filename')
for page_layout in extract_pages(pdf_filename, laparams=self.params):
for element in page_layout:
if isinstance(element, LTTextBoxHorizontal):
text_string = str(element.get_text()).strip()
text_x_pos = element.x0
text_y_pos = element.y0
text_bbox = element.bbox
# Create a new feature for each text block found
new_feature = feature.clone()
new_feature.setAttribute('page_number', page_layout.pageid)
new_feature.setAttribute('text_x_pos', text_x_pos)
new_feature.setAttribute('text_y_pos', text_y_pos)
new_feature.setAttribute('text_bbox', str(text_bbox))
new_feature.setAttribute('text_string', text_string)
self.pyoutput(new_feature)
def close(self):
pass
You'll want to expose the following attributes in the PythonCaller:
- text_x_pos
- text_y_pos
- text_string
- text_bbox
- page_number
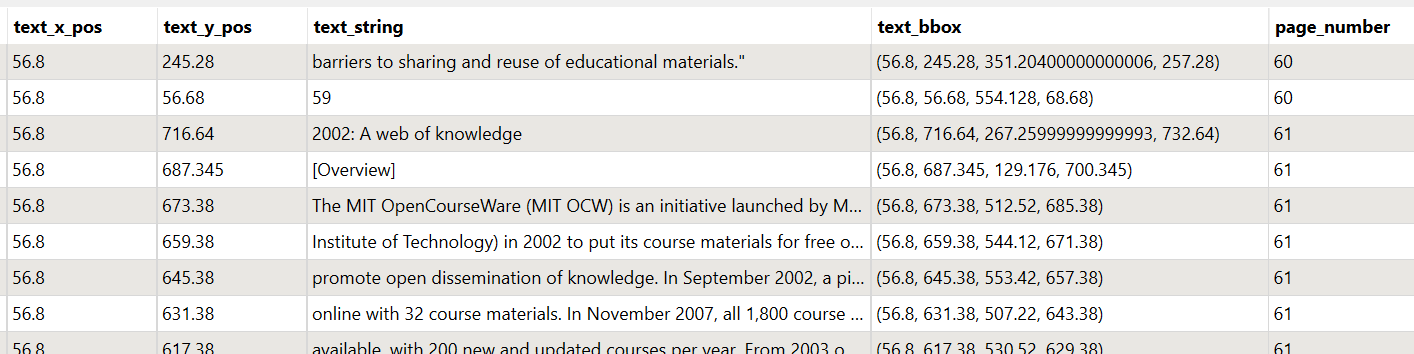
Sample output:
 To install pdfminer.six, open a command prompt as local admin in the FME installation folder:
To install pdfminer.six, open a command prompt as local admin in the FME installation folder:
fme python -m pip install pdfminer.six
See also: https://docs.safe.com/fme/html/FME-Form-Documentation/FME-Form/Workbench/Installing-Python-Packages.htm
Documentation for pdfminer.six: https://pdfminersix.readthedocs.io/en/latest/index.html





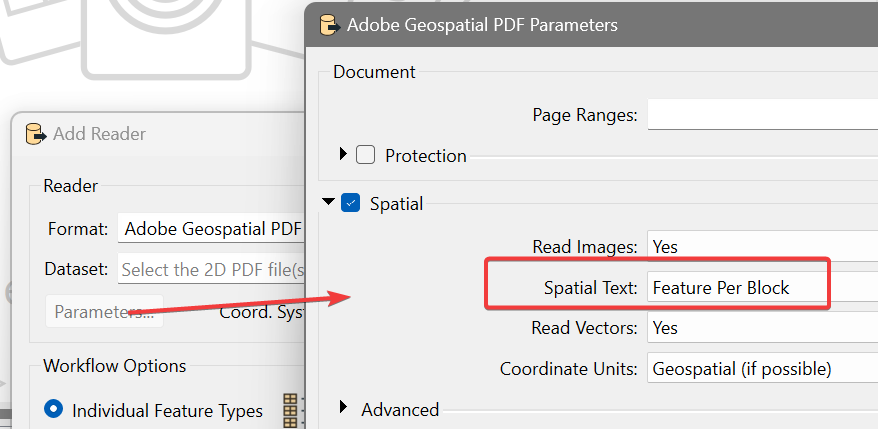 In theory, that should fix it, but my experience has been mixed, in particular with narrow fonts or particular page sizes. For some documents, the only reliable results I got was from this Python module, which is really exceptionally good at locating text blocks:
In theory, that should fix it, but my experience has been mixed, in particular with narrow fonts or particular page sizes. For some documents, the only reliable results I got was from this Python module, which is really exceptionally good at locating text blocks: