


Hello,
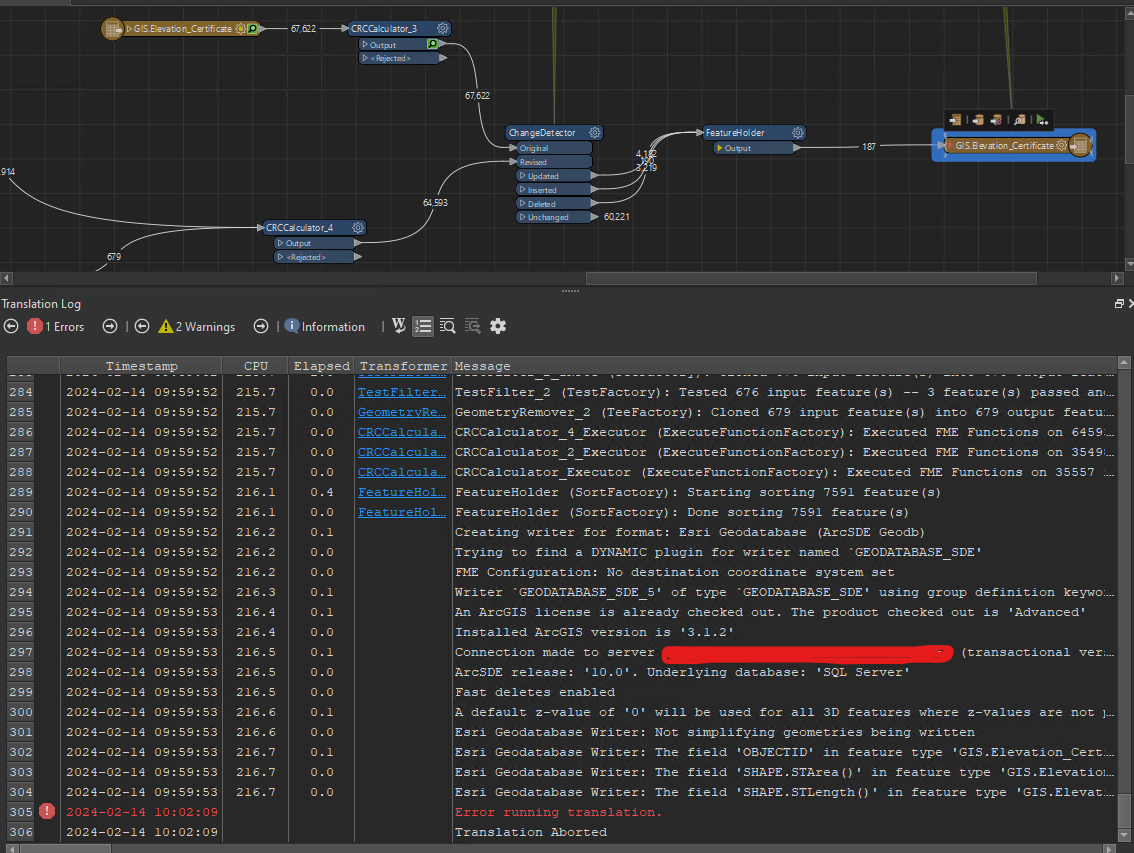
We have been troubleshooting this FME translation for a while and can’t figure out a solution. The Inserted, Deleted features of the ChangeDetector write reasonably quickly but the Update features are writing so slow it will be unusable, GIF for reference.
Things we’ve tried without any differences:
Indexing all fields in ArcCatalog
Indexing Just the Match Column fields (3 Fields to make a Unique ID)
Indexing and using a CRCCalculator field for the Match Columns
Adding a FeatureHolder after the ChangeDetector
Adding a AttributeManager after the ChangeDetector removing unused fields
Writing to a File Geodatabase (SDE is ultimately the goal and being used in the gif below)
Not Checking the Geometry in the ChangeDetector
Changing Transaction types in the Writer
Changing and testing various other settings in the transformers and writers
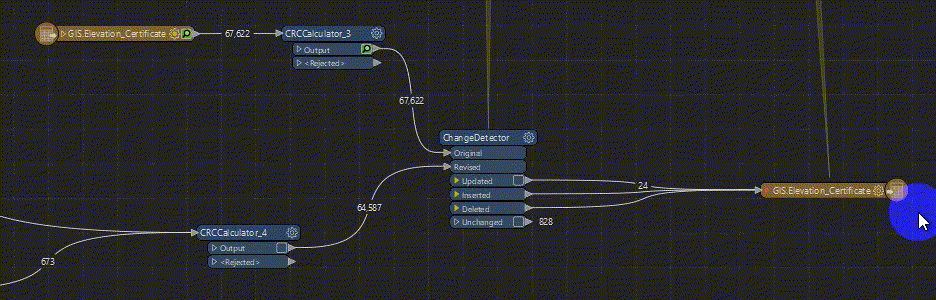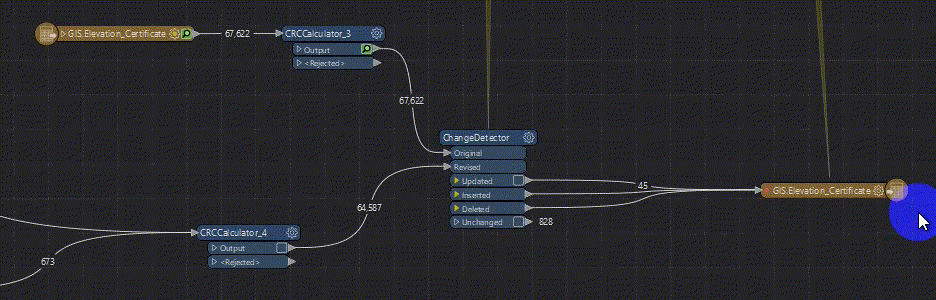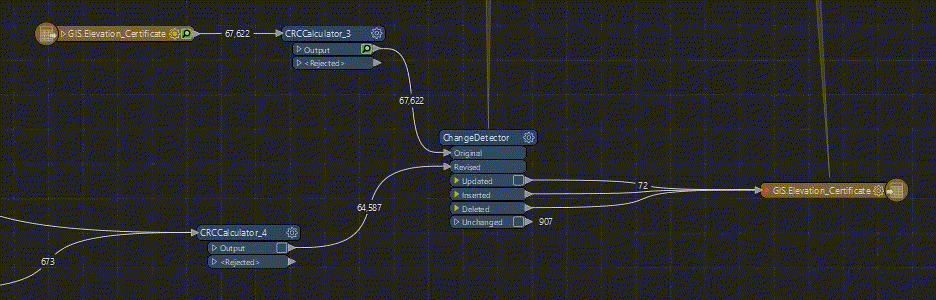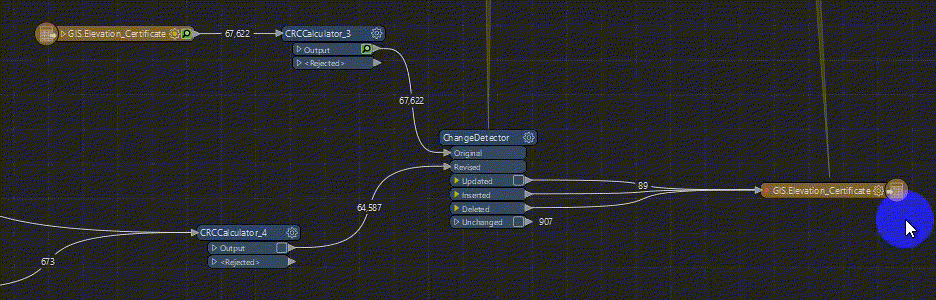
Thank you for any suggestions!!







