Hi guys,
I need to convert the current source data I have which comes in the following format and need to it to come out as the output below.
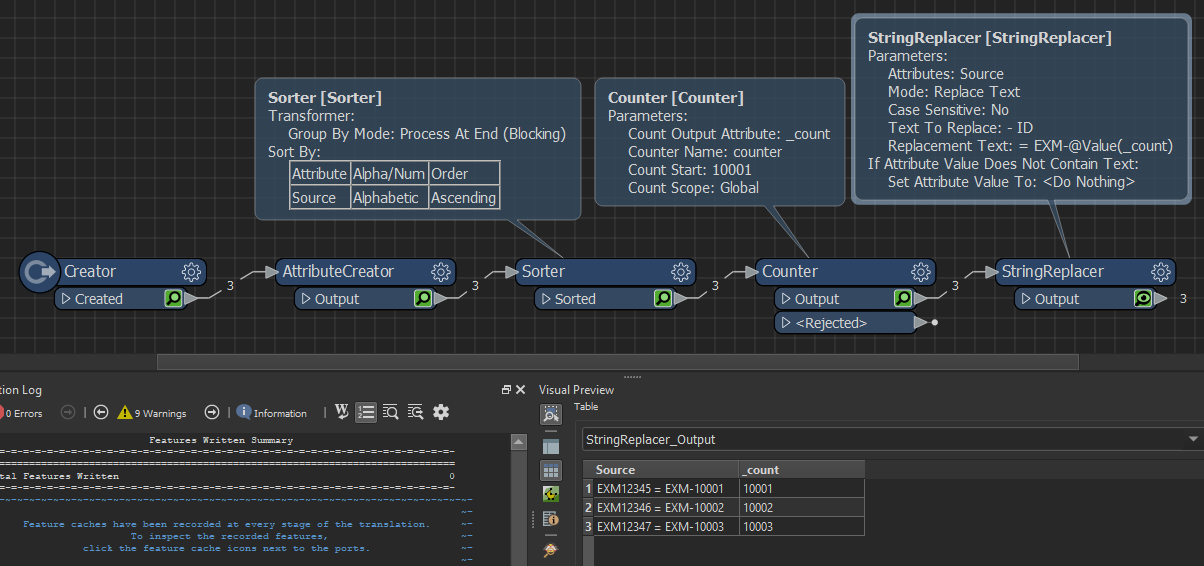
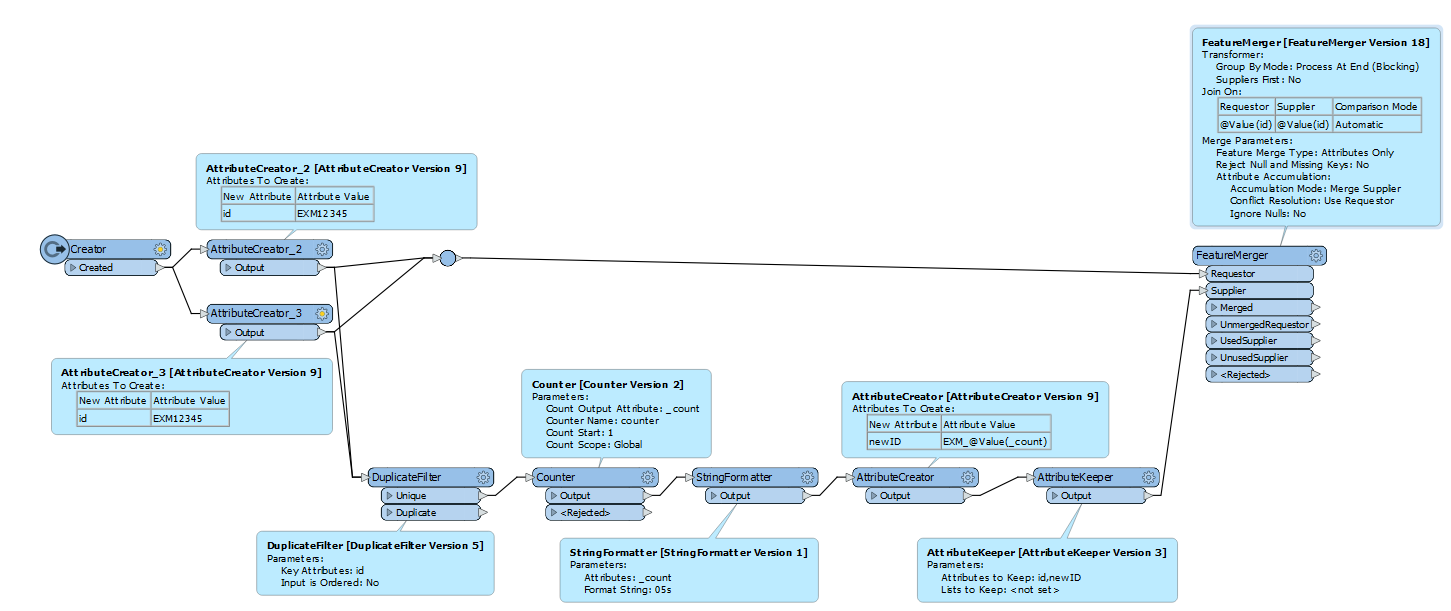
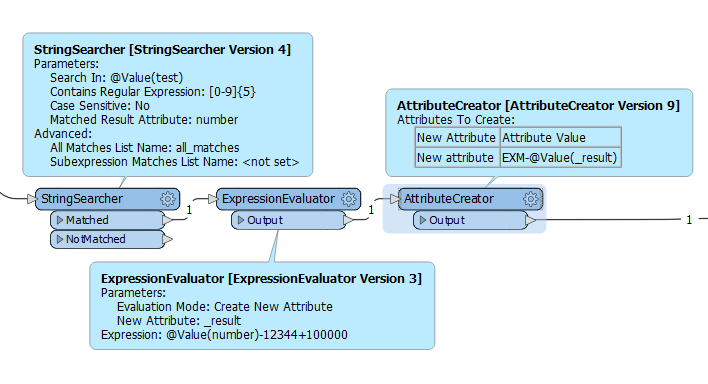
The conversion aspect of it I can get working but the issue is I want a concurrent list of IDs that is based on the source data. So all the outputs should be unique unless they are the same as the source data. What would be the best way to do this? Using the substring extractor and substring replacer has worked to a certain extent but not to complete convert all the Ids to the suggested output of 9 digit example below
Source Data
EXM12345 - ID
EXM12346 - ID
EXM12347 - ID
Output required
EXM-10001 - ID required
EXM-10002- ID required
EXM-10003- ID required
Once mapped
EXM12345 = EXM-10001
EXM12346 = EXM-10002
EXM12347 = EXM-10003