Hi all,
I would like to add a field to my vector data assigning a sequential ID to duplicate values. However I would like to ignore unique values leaving them with a COUNT of 0.
This table can hopefully explain what I would like to achieve better than me attempting to write it!
VALUECOUNT103051525354607172
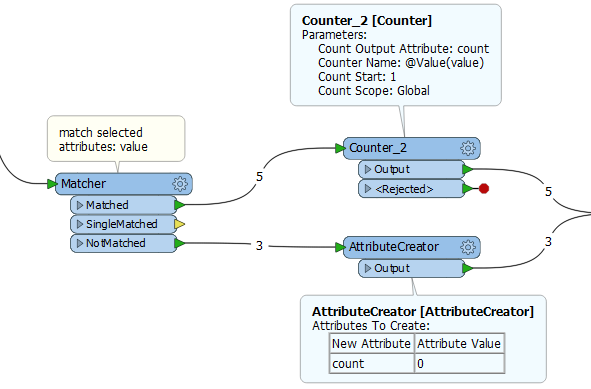
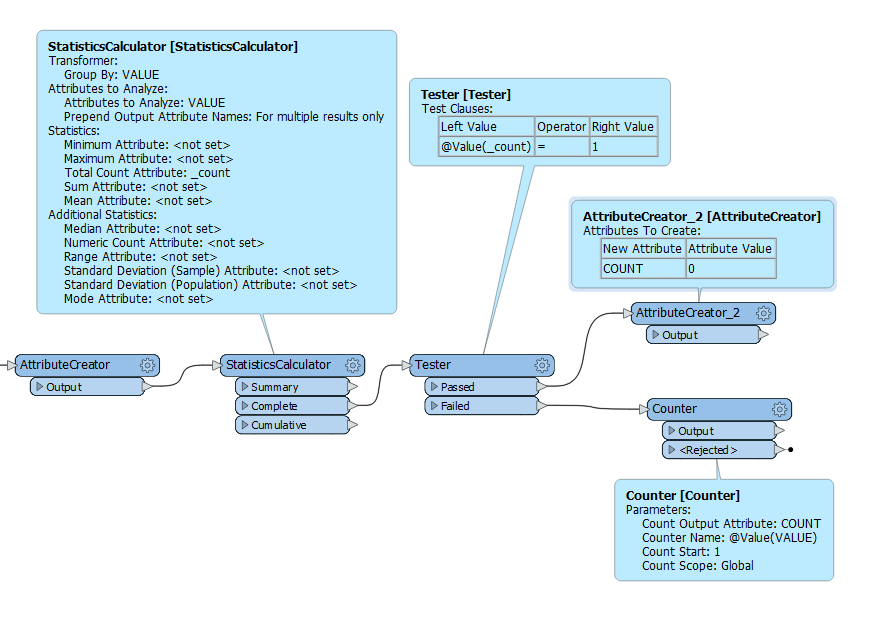
I started off with a Statistics Calculator grouping by my VALUE using the Total Count Attribute and the Cumulative output port. This counts each unique value sequentially but it also assigns a COUNT of 1 to unique values.
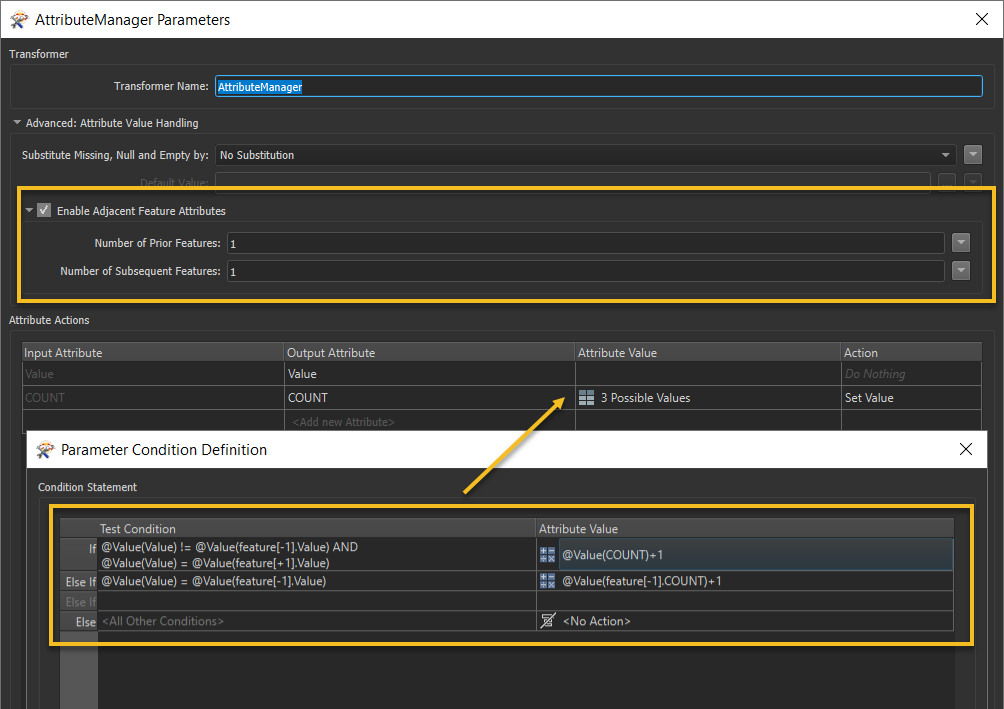
Is there another way of finding duplicates apart from the Duplicate Filter first? The Duplicate Filter doesn't appear to filter the truly unique values from duplicates. As in a the first VALUE of 7 and 5 would go through the unique port then the further 7 and 5 values would pass through the duplicate port.
I hope this makes sense to someone!
FME version 2019.1.0.0